 MENU
MENU


NOTE!
Click on MENU to Browse between Subjects...17CS562 - ARTIFICIAL INTELLIGENCE
Answer Script for Module 2
Solved Previous Year Question Paper
CBCS SCHEME
ARTIFICIAL INTELLIGENCE
[As per Choice Based Credit System (CBCS) scheme]
(Effective from the academic year 2019 -2020)
SEMESTER - V
Subject Code 17CS562
IA Marks 40
Number of Lecture Hours/Week 03
Exam Marks 60
These Questions are being framed for helping the students in the "FINAL Exams" Only
(Remember for Internals the Question Paper is set by your respective teachers).
Questions may be repeated, just to show students how VTU can frame Questions.
- ADMIN
We now have an easy way of determining that two literals are contradictory--they are if one of them can be unified with the negation of the other, So, for example, man(x) and a man(Spot) are contradictory, since man(x) and man(Spot) can be unified. This corresponds to the intuition that says that man(x) cannot be true for all x if there is known to be some x, say Spot, for which man(x) is false. Thus in order to use resolution for expressions in the predicate logic, we use the unification algorithm to locate pairs of literals that cancel out.
We also need to use the unifier produced by the unification algorithm to generate the resolvent clause. For example, suppose we want to resolve two clauses:
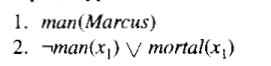

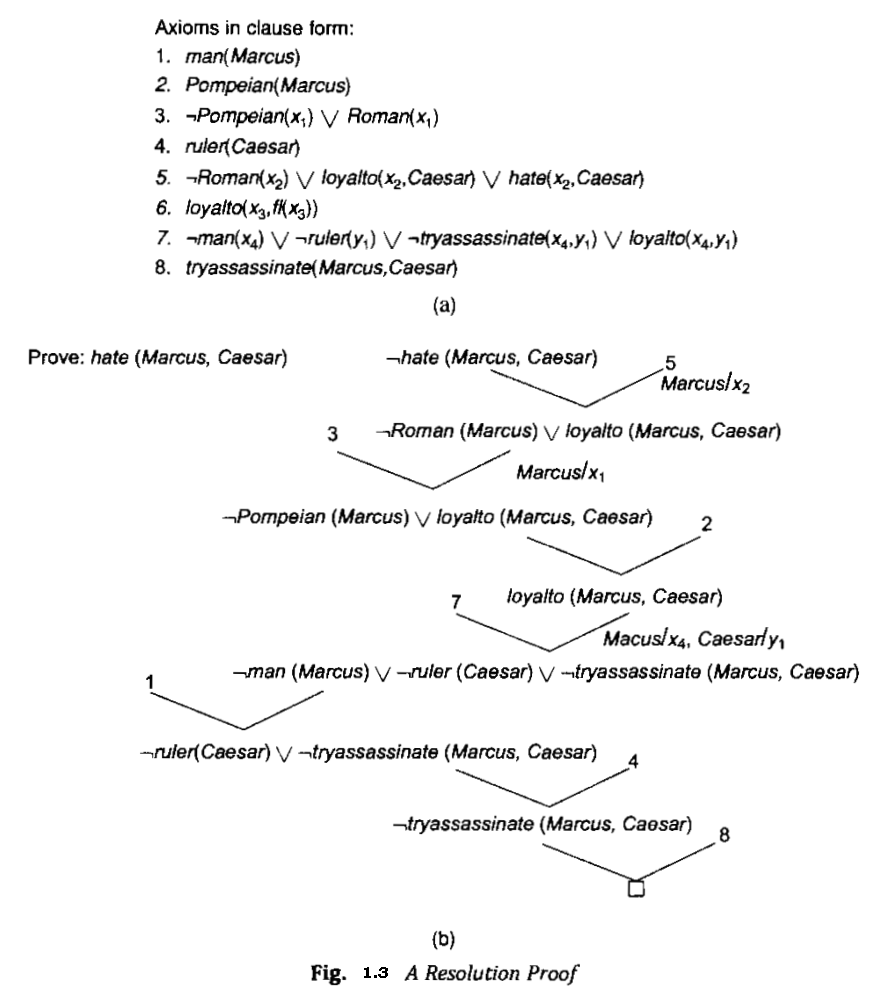


to the set of available clauses and begun the resolution process. But immediately we notice that there are no clauses that contain a literal involving 7hate. Since the resolution process can only generate new clauses that are composed of combinations of literals from already existing clauses, we know that no such clause can be generated and thus we conclude that hate(Marcus,Caesar) will not produce a contradiction with the known statements.
Matching
I. Till now we have used search to solve the problems as the application of appropriate rules.
II. We applied them to individual problem states to generate new states to which the rules can then be applied, until a solution is found.
III. We suggest that a clever search involves choosing from among the rules that can be applied at a particular point, but we do not talk about how to extract from the entire collection of rules those that can be applied at a given point.
IV. Different matching processes are,
A. Indexing
B. Matching with variables
C. Complex and approximate matching Conflict resolution
Indexing
I. Do a simple search through all the rules, comparing each one‟s precondition to the current state and extracting all the ones that match.
II. But this has two problems
a. In order to solve very interesting problems, it will be necessary to use a large number of rules, scanning through all of them at every step of the search would be hopelessly inefficient.
b. It is not always immediately obvious whether a rule‟s preconditions are satisfied by a particular state.
III. To solve the first problem, use simple indexing. Eg. In Chess, combine all moves at a particular board state together.
Matching with Variables
I. The problem of selecting applicable rules is made more difficult when preconditions are not stated as exact descriptions of particular situations but rather describe properties that the situations must have.
II. Then we need to match a particular situation and the preconditions of a given situation.
III. In many rules based systems, we need to compute the whole set of rules that match the current state description. Backward Chaining Systems usually use depth-first backtracking to select individual rules, but forward chaining systems use Conflict Resolution Strategies.
One efficient algorithm RETE, which gains efficiency from three major sources.
1)
The temporal nature of data:
Whenever we apply a rule on the current state. Some properties will be added and some other properties are deleted and some times the rule will not be applicable. If no rule will not be applicable to the problem, the RETE process will tell which rule applicable to the pre-state is not applicable to the current state.
2)
Structural similarities in rules:
In the similarities of the rules, data can be considered as
i) Tiger(x) mammal(x) ^ stripes(x) ^ carnivorous(x)
ii) Jaguar(x) mammal(x) ^ sports (x) ^ carnivorous(x)
Ex: For this consider
Frame-I frame II
Similarities similarities
Mammal(x) stripes(x)
Carnivorous(x) sports(x)
In RETE process , first we have to verify the dissimilarities rules and after that we verify the similar rules and also we have to identify which rule have less no of sub goals and which rule has more no of sub goals.
3)
Persistence in binding up of variables:-
There may be variable binding conflicts that prevent the rule from firing. For example, consider the following facts.
Son (john, David)
Son (bill, Ellen) and we can compare to son(x,y) and son(y,z) The individual preconditions of the rule is
x: y : son(x, y) ^ son(y, z)grandparent(y, z).
Where x=John and y=David.
For this first time, x, y has initial values after the completion of first predicate here x,y are binded variables.
For the second time, if y=bill which is not accepted because „y‟ has already a value is given. So, we can not give another value „y‟. Therefore, „y‟ is a binding up variable. The RETE takes the binding up of variables to the problem solving.
Complex & Approximate Matching
I. A more complex matching process is required when the preconditions of a rule specify required properties that are not stated explicitly in the description of the current state. In this case, a separate set of rules must be used to describe how some properties can be inferred from others.
II. An even more complex matching process is required if rules should be applied if their preconditions approximately match the current situation. Example of listening to a recording of a telephonic conversation.
III. For some problems, almost all the action is in the matching of the rules to the problem state. Once that is done, so few rules apply that the remaining search is trivial.
Example
: ELIZA

The conversion between ELIZA, an A.I problem and the user. Here ELIZA will try to match the left side of the rule against the sentence and use the correct right side rule to generate a response. Let us considering the following ELIZA rules.
|
(x me y) |
|
(X you y) |
|
(I remember x) |
|
(Why do remember x just now?) |
|
(My family -member is y) |
|
(Who else is your family is y?) |
Suppose the use say "I remember Mary".
How ELIZA will try
to match the above response to the left hand side of the given rules. It
finds that it matches to the first rule and now it take the right hand side
ask, "Why do rememberMary just now?"
This is the why how
the conversion proceeds taking into consideration the approximate matching.
Conflict Resolution
I. The result of the matching process is a list of rules whose antecedents have matched the current state description along with whatever variable binding were generated by the matching process.
II. It is the job of the search method to decide on the order in which the rules will be applied. But sometimes it is useful to incorporate some of the decision making into the matching process. This phase is called conflict resolution.
III. There are three basic approaches to the problem of conflict resolution in the production system
I. Assign a preference based on the rule that matched.
II. Assign a preference based on the objects that matched.
III. Assign a preference based on the action that the matched rule would perform.
a) Preference based on rules:
a. Here we consider the rule in the order they are given or we given some priority
b. to special case rules.
b) Performance based on object:
a. Here we use key words to match into the rules. Consider the example of
b. ELIZA.
c) Performance based on states:
a. In this case we consider all rules that are waiting, which gives some states.
b. Here a heuristic function we can decide which state is the best.
A good system for the representation of knowledge in a particular domain should possess the following four properties:
I. Representational Adequacy
: the ability to represent
tall of the kinds of knowledge that are needed in that domain.
II. Inferential Adequacy:
the ability to manipulate the
representational structures in such a way as to derive new structures
corresponding to new knowledge inferred from old.
III. Inferential Efficiency
: the ability to incorporate
into the knowledge structure additional information that can be used to
focus the attention of the inference mecha-nisms in the most promising
directions.
IV. Acquisitional Efficiency:
the ability to acquire new
information easily. The simplest case involves direct insertion, by a
person, of new knowledge into the database. Ideally, the program itself
would be able to control knowledge acquisition.
Unfortunately, no single system that optimizes all of the capabilities for all kinds of knowledge has yet been found. As a result, multiple techniques for knowledge representation exist. Many programs rely on more than one technique. In the chapters that follow, the most important of these techniques are described in detail. But in this section, we provide a simple, example-based introduction to the important ideas.
The Different Approaches to Knowledge Representation (KR) are as follows:
a. Simple Relational Knowledge
b. Inheritable Knowledge
c. Inferential Knowledge
d. Procedural Knowledge
I.
Simple Relational Knowledge
The simplest way to represent declarative facts is as a set of relations of the same sort used in database systems.
Figure 3.1 shows an example of such a relational system.
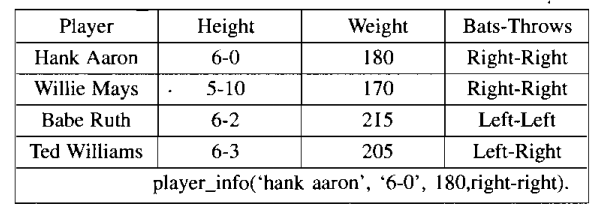
Fig 3.1: Simple Relational Knowledge and a sample fact in Prolog
The reason that this representation is simple is that standing alone it provides very weak inferential capabilities. But knowledge represented in this form may serve as the input to more powerful inference engines.
For example, given just the facts of Fig.3.1, it is not possible even to answer the simple question, "Who is the heaviest player?" But if a procedure for finding the heaviest player is provided, then these facts will enable the procedure to compute an answer. If, instead, we are provided with a set of rules for deciding which hitter to put up against a given pitcher (based on right- and left-handedness, say), then this same relation can provide at least some of the information required by those rules.
Providing support for relational knowledge is what database systems are designed to do. Thus we do not need to discuss this kind of knowledge representation structure further here. The practical issues that arise in linking a database system that provides this kind of support to a knowledge representation system that provides some of the other capabilities that we are about to discuss have already been solved in several commercial products.
II.
Inheritable Knowledge
a. In the inheritable knowledge approach, all data must be stored into a hierarchy of classes.
b. All classes should be arranged in a generalized form or a hierarchal manner.
c. In this approach, we apply inheritance property.
d. Elements inherit values from other members of a class.
e. This approach contains inheritable knowledge which shows a relation between instance and class, and it is called instance relation.
f. Every individual frame can represent the collection of attributes and its value.
g. In this approach, objects and values are represented in Boxed nodes.
h. We use Arrows which point from objects to their values.
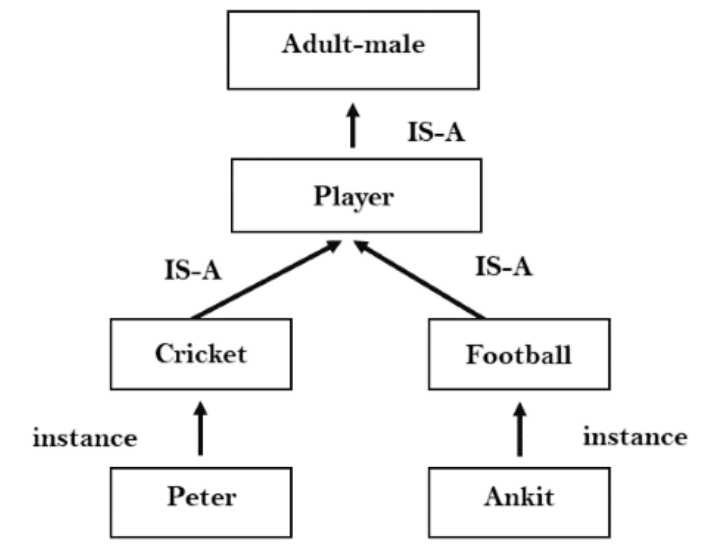
Fig 3.2: Inheritance KR
III.
Inferential Knowledge
Property inheritance is a powerful form of inference, but it is not the only useful form. Sometimes all the power of traditional logic (and sometimes even more than that} is necessary to describe the inferences that are needed.
Figure 3.3 shows two examples of the use of first-order predicate logic to represent additional! knowledge about baseball.

Fig 3.3: Inferential KR
Of course, this knowledge is useless unless there is also an inference procedure that can exploit it (just as the default knowledge in the previous example would have been useless without our algorithm for moving through the knowledge structure).
The required inference procedure now 1s one that implements the standard logical rules of inference. There are many such procedures, some of which reason forward trom given facts to conclusions, others of which reason backward from desired conclusions to given facts.
One of the most commonly used of these procedures is resolution, which exploits a proof by contradiction strategy.
IV.
Procedural Knowledge
a. Procedural knowledge approach uses small programs and codes which describes how to do specific things, and how to proceed.
b. In this approach, one important rule is used which is If-Then rule.
c. In this knowledge, we can use various coding languages such as LISP language and Prolog language.
d. We can easily represent heuristic or domain-specific knowledge using this approach.
e. But it is not necessary that we can represent all cases in this approach.
|
|
|
|
|
|
Data-driven |
Goal driven |
|
|
New Data |
Uncertain conclusion |
|
|
Conclusion that must follow |
Facts to support the conclusions |
|
|
Opportunistic |
Conservative |
|
|
Incipient to consequence |
Consequence to incipient |
ISSUES IN KNOWLEDGE REPRESENTATION ARE AS FOLLOWS:
I. Are any attributes of objects so basic that they occur in almost every problem domain? If there are, we need to make sure that they are handled appropriately in each of the mechanisms we propose. If such attributes exist, what are they?
II. Are there any important relationships that exist among attributes of objects?
III. At what level should knowledge be represented? Is there a good set of primitives into which all knowledge can be broken down? Is it helpful to use such primitives?
IV. How should sets of objects be represented?
V. Given large amount of knowledge stored in a database, how can relevant parts be accessed when they are needed?
Brief Explanation for UNDERSTANDING
I. Attributes
a. Are they basic?
b. Are they occuring frequently?
c. How are they properly represented?
d. E.g., ISA, INSTANCE
II. Relationship among attributes
a. Inverse
b. Existence in a ISA hierarchy
c. Techniques for reasoning about value
d. Single valued attributes
III. Level of KR
a. Use of primitives to represent knowledge
b. Can knowledge be broken down into a defined set of primitives
c. How such primitives help in KR
IV. Object Representation
V. How to access knowledge from repository
a. Use of primitives to represent knowledge
b. Can knowledge be broken down into a defined set of primitives
c. How such primitives help in KR
Below Page NAVIGATION Links are Provided...
All the Questions on Question Bank Is SOLVED
Follow our Instagram Page:
FutureVisionBIE
https://www.instagram.com/futurevisionbie/
Message: I'm Unable to Reply to all your Emails
so, You can DM me on the Instagram Page & any other Queries.