 MENU
MENU


NOTE!
Click on MENU to Browse between Subjects...17CS562 - ARTIFICIAL INTELLIGENCE
Answer Script for Module 4
Solved Previous Year Question Paper
CBCS SCHEME
ARTIFICIAL INTELLIGENCE
[As per Choice Based Credit System (CBCS) scheme]
(Effective from the academic year 2019 -2020)
SEMESTER - V
Subject Code 17CS562
IA Marks 40
Number of Lecture Hours/Week 03
Exam Marks 60
These Questions are being framed for helping the students in the "FINAL Exams" Only
(Remember for Internals the Question Paper is set by your respective teachers).
Questions may be repeated, just to show students how VTU can frame Questions.
- ADMIN
Definition of a Script:
A script is a structure that describes a stereotyped sequence of events in
a particular context. A script consists of a set of slots. Associated with
each slot may be some information about what kinds of values it may contain
as well as a default value to be used if no other information is available.
The components of a Script are as follows:
i. Entry conditions
: Conditions that must, in general, be
satisfied before the events described in the script can occur.
ii. Result:
Conditions that will, in general, be true
after the events described in the script have occurred.
iii. Props:
Slots representing objects that are involved
in the events described in the script. The presence of these objects can be
inferred even if they are not mentioned explicitly.
iv. Roles:
Slots representing people who are involved in
the events described in the script. The presence of these people, too, can
be inferred even if they are not mentioned explicitly. If specific
individuals are mentioned, they can be inserted into the appropriate slots.
v. Track:
The specific variation on a more general pattern
that is represented by this particular script. Different tracks of the same
script will share many but not all components.
vi. Scenes:
The actual sequences of events that occur. The
events are represented in conceptual dependency formalism.
The minimax search procedure is a depth-first, depth-limited search procedure. The idea is to start at the current position and use the plausible-move generator to generate the set of possible successor positions. Now we can apply the static evaluation 'unction to those positions and simply choose the best one. After doing so, we can back that value up to the starting position to represent our evaluation of it. The starting position is exactly as good for us as the position generated by the best move we can make next. Here we assume that the static evaluation function returns large values to indicate good situations for us, so our goal is to maximize the value of the static evaluation function of the next board position.
Algorithm: MINIMAX(Position, Depth, Player)
2.1. If DEEP-ENOUGH(Position, Depth), then return the structure
VALUE=STATIC(Position, Player),
PATH = nil
This indicates that there is no path from this node and that its value is that determined by the static evaluation function.
2.2. Otherwise, generate one more ply of the tree by calling the function MOVE-GEN(Position Player) and setting SUCCESSORS to the list it returns.
2.3. If SUCCESSORS is empty, then there are no moves to be made, so return the same structure that would have been returned if DEEP-ENOUGH had returned true.
2.4. 1f SUCCESSORS is not empty, then examine each element in turn and keep track of the best one. This is done as follows.
Initialize BEST-SCORE to the minimum value that STATIC can return. It will be updated to reflect the best score that can be achieved by an element of SUCCESSORS.
For each element SUCC of SUCCESSORS, do the following:
(a) Set RESULT-SUCC to
MINIMAX(SUCC, Depth + 1, OPPOSITE(Player))
This recursive call to MINIMAX will actually carry out the exploration of SUCC.
(b) Set NEW-VALUE to - VALUE(RESULT-SUCC). This will cause it to reflect the merits of the position from the opposite perspective from that of the next lower level.
(c) If NEW-VALUE > BEST-SCORE, then we have found a successor that is better than any that have been examined so far. Record this by doing the following:
(i) Set BEST-SCORE to NEW-VALUE.
(ii) The best known path is now from CURRENT to SUCC and then on to the appropriate path down from SUCC as determined by the recursive call to MINIMAX. So set BEST-PATH to the result of attaching SUCCto the front of PATH(RESULT-SUCC).
2.5. Now that all the successors have been examined, we know the value of Position as well as which path to take from it. So return the structure
VALUE = BEST-SCORE
PATH = BEST-PATH
When the initial call to MINIMAX returns, the best move from CURRENT is the first element on PATH.
The MINIMAX procedure just described is very simple. But its performance can be improved significantly with a few refinements.
The Rules of Conceptual Dependency (CD) are as follows:
Rule 1
describes the relationship between an actor and the event he or she causes.
This is a two-way dependency since neither actor nor event can be
considered primary. The letter p above the dependency link indicates past
tense.
Rule 2
describes the relationship between a PP and a PA that is being asserted to
describe it. Many state descriptions, such as height, are represented in CD
as numeric scales.
Rule 3
describes the relationship between two PPs, one of which belongs to the set
defined by the other.
Rule 4
describes the relationship between a PP and an attribute that has already
been predicated of it. The direction of the arrow is toward the PP being
described.
Rule 5
describes the relationship between two PPs, one of which provides a
particular kind of information about the other. The three most common types
of information to be provided in this way are possession (shown as
POSS-BY), location (shown as LOC), and physical containment (shown as
CONT). The direction of the arrow is again toward the concept being
described.
Rule 6
describes the relationship between an ACT and the PP that is the object of
that ACT. The direction of the arrow is toward the ACT since the context of
the specific ACT determines the meaning of the object relation.
Rule 7
describes the relationship between an ACT and the source and, the recipient
of the ACT.
Rule 8
describes the relationship between an ACT and the instrument with which it
is performed. The instrument must always be a full conceptualization (i.e.
it must contain an ACT), not just a single physical object.
Rule 9
describes the relationship between an ACT and its physical source and
destination.
Rule 10
represents the relationship between a PP and a state in which it started
and another in which it ended.
Rule 11
describes the relationship between one conceptualization and another that
causes it. Notice that the arrows indicate dependency of one
conceptualization on another and so point in the opposite direction of the
implication arrows. The two forms of the mule describe the cause of an
action and the cause of a state change.
Rule 12
describes the relationship between a conceptualization and the time at
which the event it describes occurred.
Rule 13
describes the relationship between one conceptualization and another that
is the time of the first. The example for this rule also shows how CD
exploits a model of the human information processing system; see is
represented as the transfer of information between the eyes and the
conscious processor.
Rule 14
describes the relationship between a conceptualization and the place at
which it occurred.
There are many reasons, among them:
Brittleness:
Specialized knowledge-based systems are brittle. They cannot cope with
novel situations, and their performance degradation is not graceful.
Programs built on top of deep, common sense knowledge about the world
should rest on firmer foundations.
Form and Content:
The techniques we have seen so far for representing and using knowledge may
or may not be sufficient for the purposes of AI. One good way to find out
is to start coding large amounts of common sense knowledge and see where
the difficulties crop up. In other words, one strategy is to focus
temporarily on the content of knowledge bases rather than on their form.
Shared Knowledge:
Small knowledge-based systems must make simplifying assumptions about how
to represent things like space, time, motion, and structure. If these
things can be represented once at a very high level, then domain-specific
systems can gain leverage cheaply. Also, systems that share the same
primitives can communicate easily with one another.
A number of ideas for searching two-player game trees have led to new algorithms for single-agent heuristic search. One such idea is iterative deepening, originally used in a program called CHESS 4.5. Rather than searching to a fixed depth in the game tree, CHESS 4,5 first searched only a single ply, applying its static evaluation function to the result of each of its possible moves. It then initiated a new minimax search, this time to a depth of two ply.
This was followed by a three-ply search, then a four-ply search, etc. The name "iterative deepening" derives from the fact that on each iteration, the tree is searched one level deeper. The Below figure depicts this process.
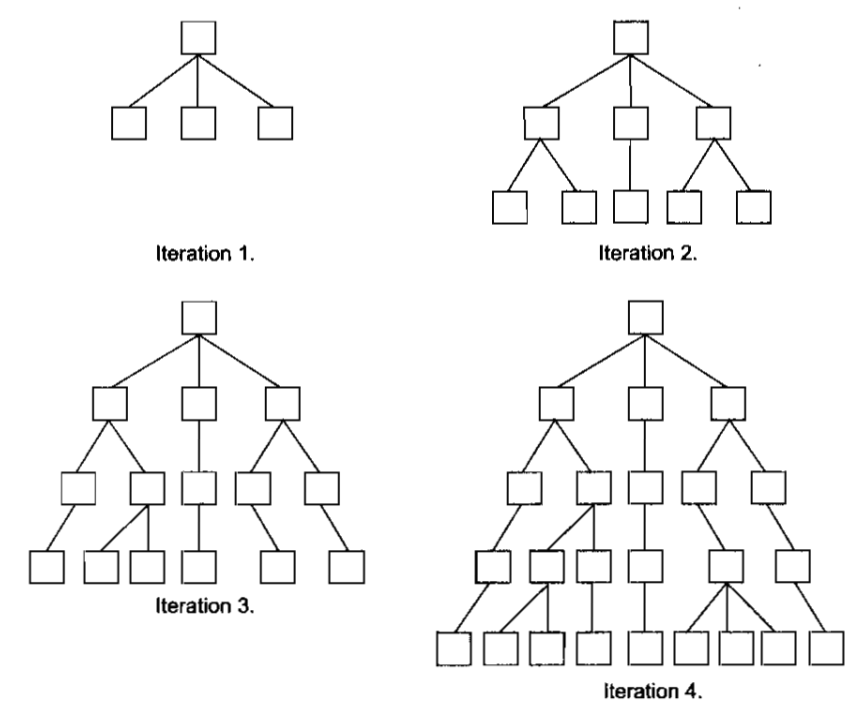
Fig 5.1 : Iterative Deepening
On the face of it, this process seems wasteful. Why should we be interested in any iteration except the final one? There are several reasons. First, game-playing programs are subject to time constraints. For example, a chess program may be required to complete all its moves within two hours. Since it is impossible to know in advance how long a fixed-depth tree search will take (because of variations in pruning efficiency and the need for selective search), a program may find itself running out of time. With iterative deepening, the current search can be aborted at any time and the best move found by the previous iteration can be played. Perhaps more importantly, previous iterations can provide invaluable move-ordering constraints. If one move was judged to be superior to its siblings in a previous iteration, it can be searched first in the next iteration. With effective ordering, the alpha-beta procedure can prune many more branches, and total search time can be decreased drastically. This allows more time for deeper iterations.
Algorithm: Depth-First Iterative Deepening
Step 1. Set SEARCH-DEPTH = 1.
Step 2. Conduct a depth-first search to a depth of SEARCH-DEPTH. If a solution path is found, then return it.
Step 3. Otherwise, increment SEARCH-DEPTH by I and go to step 2.
Clearly, DFID will find the shortest solution path to the goal state. Moreover, the maximum amount of memory used by DFID is proportional to the number of nodes in that solution path. The only disturbing fact is that all iterations but the final one are essentially wasted. However, this is not a serious problem. The reason is that most of the activity during any given iteration occurs at the leaf-node level. Assuming a complete tree, we see that there are as many leaf nodes at level n as there are total nodes in levels I through n. Thus, the work expended during the nth iteration is roughly equal to the work expended during all previous iterations, This means that DFID is only slower than depth-first search by a constant factor. The problem with depth-first Search is that there is no way to know in advance how deep the solution lies in the search space. DFID avoids the problem of choosing cut offs without sacrificing efficiency, and, in fact, DFID is the optimal algorithm (in terms of space and time) for uninformed search.
Algorithm: Iterative-Deepening-A*
1. Set THRESHOLD=the heuristic evaluation of the start state.
2. Conduct a depth-first search, pruning any branch when its total cost function (g + A') exceeds THRESHOLD. If a solution path is found during the search, return it.
3. Otherwise, increment THRESHOLD by the minimum amount it was exceeded during the previous step, and then go to Step 2.
Like A*, Iterative-Deepening-A* (IDA*) is guaranteed to find an optimal solution, provided that h' is an admissible heuristic. Because of its depth-first search technique, [DA* is very efficient with respect to space. IDA* was the first heuristic search algorithm to find optimal solution paths for the 15-puzzle (a 4x4 version of the 8-puzzle) within reasonable time and space constraints.
Below Page NAVIGATION Links are Provided...
All the Questions on Question Bank Is SOLVED
Follow our Instagram Page:
FutureVisionBIE
https://www.instagram.com/futurevisionbie/
Message: I'm Unable to Reply to all your Emails
so, You can DM me on the Instagram Page & any other Queries.