 MENU
MENU


NOTE!
Click on MENU to Browse between Subjects...17CS562 - ARTIFICIAL INTELLIGENCE
Answer Script for Module 5
Solved Previous Year Question Paper
CBCS SCHEME
ARTIFICIAL INTELLIGENCE
[As per Choice Based Credit System (CBCS) scheme]
(Effective from the academic year 2019 -2020)
SEMESTER - V
Subject Code 17CS562
IA Marks 40
Number of Lecture Hours/Week 03
Exam Marks 60
These Questions are being framed for helping the students in the "FINAL Exams" Only
(Remember for Internals the Question Paper is set by your respective teachers).
Questions may be repeated, just to show students how VTU can frame Questions.
- ADMIN
The Steps involved in Natural Language understanding process are as follows:
Morphological Analysis:
Individual words are analysed into their components, and non-word tokens,
such as punctuation, are separated from the words.
Syntactic Analysis:
Linear sequences of words are transformed into structures that show how the
words relate to each other. Some word sequences may be rejected if they
violate the language's rules for how words may be combined. For example, an
English syntactic analyser would reject the sentence "Boy the go the to
store."
Semantic Analysis:
The structures created by the syntactic analyser are assigned meanings. In
other words, a mapping is made between the syntactic structures and objects
in the task domain. Structures for which no such mapping is possible may be
rejected. For example, in most universes, the sentence "Colorless green
ideas sleep furiously" [Chomsky, 1957] would be rejected as semantically
anomolous.
Discourse Integration:
The meaning of an individual sentence may depend on the sentences that
precede it and may influence the meanings of the sentences that follow it.
For example, the word "it" in the sentence, "John wanted it," depends on
the prior discourse context, while the word "John" may influence the
meaning of later sentences (such as, "He always had.")
Pragmatic Analysis:
The structure representing what was said is reinterpreted to determine what
was actually meant. For example, the sentence "Do you know what time it
is?" should be interpreted as a request to be told the time.
Knowledge acquisition itself includes many different activities. Simple storing of computed information, or rote learning, is the most basic learning activity. Many computer programs, e.g., database systems, can be said to "learn" in this sense, although most people would not call such simple storage learning. However, many AT programs are able to improve their performance substantially through rote-learning techniques.
Knowledge acquisition is the process to extract structure and organize the knowledge from various sources of human experts and is also consider as the process of adding new knowledge and to change which was anonymously acquired to the knowledge base. It is mainly used in the system development. The purpose of knowledge acquisition is to elaborate the capability of the system to improve the specific task of the performance consisting of facts, rules, concepts, procedures, heuristics, formulas, relationships or other useful information.
Knowledge acquisition process facilitates the assimilation of knowledge and experiences of different specialties. For example, an agricultural diagnostic expert system requires the integration of specialists in various fields such as nutrition, plant pathology, entomology, breading, and production. When problem occurs, the system can help the user more efficiently in identifying the cause of the problem. It then helps in consulting a document that handles a specific problem
The existing knowledge and newly acquired knowledge should be incorporated in a significant way to draw inferences from resultant body of knowledge which will be effective and many of the important conclusions for which the systems can be intended. The knowledge should be accurate, non-redundant, consistent, non-contradictory and fairly complete in the sense that it will be possible to rely reasonably
Knowledge Acquisition Technique
At the heart of the process is the interview. The heuristic model of the domain is usually extracted through a series of intense, systematic interviews, usually extending over a period of many months. Note that this assumes the expert and the knowledge engineer are not the same person. It is generally best that the expert and the knowledge engineer not be the same person since the deeper the experts' knowledge, the less able they are in describing their logic. Furthermore, in their efforts to describe their procedures, experts tend to rationalize their knowledge and this can be misleading.
General suggestions about the knowledge acquisition process are summarized in rough chronological order below:
1. Observe the person solving real problems.
2. Through discussions, identify the kinds of data, knowledge and procedures required to solve different types of problems.
3. Build scenarios with the expert that can be associated with different problem types.
4. Have the expert solve a series of problems verbally and ask the rationale behind each step.
5. Develop rules based on the interviews and solve the problems with them.
6. Have the expert review the rules and the general problem solving procedure.
7. Compare the responses of outside experts to a set of scenarios obtained from the project's expert and the ES.
Note that most of these procedures require a close working relationship between the knowledge engineer and the expert.
A third approach to concept learning is the induction of decision trees, as exemplified by the ID3 program of Quinlan [1986]. [D3 uses a tree representation for concepts, such as the one shown in Fig. 3.1. To classify a particular input, we start at the top of the tree and answer questions until we reach a leaf, where the classification is stored,
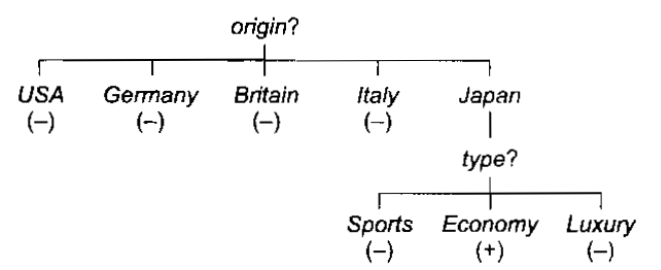
Fig: 3.1 A Decision Tree
1D3 uses an iterative method to build up decision trees, preferring simple trees over complex ones, on the theory that simple trees are more accurate classifiers of future inputs. It begins by choosing a random subset of the training examples. This subset is called the window. The algorithm builds a decision tree that correctly classifies all examples in the window. The tree is then tested on the training examples outside the window. If all the examples are classified correctly, the algorithm halts. Otherwise, it adds a number of training examples to the window and the process repeats. Empirical evidence indicates that the iterative strategy is more efficient than considering the whole training set at once.
So how does ID3 actually construct decision trees? Building a node means choosing some attribute to test. Ata given point in the tree, some attributes will yield more information than others, for example, testing the attribute color is useless if the color of a car does not help us to classify it correctly. Ideally, an attribute will separate training instances into subsets whose members share a common label (e.g., positive or negative). In that case, branching is terminated, and the leaf nodes are labelled.
There are many variations on this basic algorithm. For example, when we add a test that has more than two branches, It is possible that one branch has no corresponding training instances. In that case, we can either leave the node unlabelled, or we can attempt to guess a label based on statistical properties of the set of instances being tested at that point in the tree. Noisy input is another issue. One way of handling noisy input is to avoid building new branches if the information gained is very slight. In other words, we do not want to over complicate the tree to account for isolated noisy instances, Another, source of uncertainty is that attribute values may be unknown.
For example a patient's medical record may be incomplete. One solution is to guess the correct branch to take; another solution is to build special "unknown" branches at each node during learning.
Semantic grammars, which combine syntactic, semantic, and pragmatic knowledge into a single set of rules in the form of a grammar. The result of parsing with such a grammar is a semantic, rather than just a syntactic, description of a sentence.
Case grammars, in which the structure that is built by the parser contains some semantic information, although further interpretation may also be necessary.
Classification is the process of assigning to a particular input, the name of a class to which it belongs. The classes from which the classification procedure can choose can be described in a variety of ways. Their definition will depend on the use to which they will be put.
Classification is an important component of many problem-solving tasks. In its simplest form, it is presented as a straightforward recognition task. An example of this is the question "What letter of the alphabet is this?" But often classification is embedded inside another operation. To see how this can happen, consider a problem solving system that contains the following production rule:
If: the current goal is to get from place A to place B, and there is a
WALL separating the two places
then: look for a DOORWAY in the WALL and go through it.
To use this rule successfully, the system's matching routine must be able to identify an object as a wall. Without this, the rule can never be invoked. Then, to apply the rule, the system must be able to recognize a doorway.
Before classification can be done, the classes it will use must be defined. This can be done in a variety of ways, including:
Ø Isolate a set of features that are relevant to the task domain. Define each class by a weighted sum of values of these features. Each class is then defined by a scoring function that looks very similar to the scoring functions often used in other situations, such as game playing. Such a function has the form:
c1l1 + c2l2 + c3l 3 + ….
Each t corresponds to a value of a relevant parameter, and each c represents the weight to be attached to the corresponding 4 Negative weights can be used to indicate features whose presence usually constitutes negative evidence for a given class.
For example, if the task is weather prediction, the parameters can be such measurements as rainfall and location of cold fronts. Different functions can be written to combine these parameters to predict sunny, cloudy, rainy, or snowy weather.
Ø Isolate a set of features that are relevant to the task domain. Define each class as a structure composed of those features. For example, if the task is to identify animals, the body of each type of animal can be stored as a structure, with various features representing such things as color, length of neck, and feathers.
There are advantages and disadvantages to each of these general approaches. The statistical approach taken by the first scheme presented here is often more efficient than the structural approach taken by the second. But the second is more flexible and more extensible.
Regardless of the way that classes are to be described, it is often difficult to construct, by hand, good class definitions. This is particularly true in domains that are not well understood or that change rapidly. Thus the idea of producing a classification program that can evolve its own class definitions is appealing. This task of constructing class definitions is called concept learning, or induction. The techniques used for this task must, of course, depend on the way that classes (concepts) are described. If classes are described by scoring functions, then concept learning can be done using the technique of coefficient adjustment, however, we want to define classes structurally, some other technique for learning class definitions is necessary. In this section, we present three such techniques.
Below Page NAVIGATION Links are Provided...
All the Questions on Question Bank Is SOLVED
Follow our Instagram Page:
FutureVisionBIE
https://www.instagram.com/futurevisionbie/
Message: I'm Unable to Reply to all your Emails
so, You can DM me on the Instagram Page & any other Queries.