 MENU
MENU


NOTE!
Click on MENU to Browse between Subjects...17CS52 - COMPUTER NETWORKS
Answer Script for Module 1
Solved Previous Year Question Paper
CBCS SCHEME
COMPUTER NETWORKS
[As per Choice Based Credit System (CBCS) scheme]
(Effective from the academic year 2019 -2020)
SEMESTER - V
Subject Code 17CS52
IA Marks 40
Number of Lecture Hours/Week 04
Exam Marks 60
These Questions are being framed for helping the students in the "FINAL Exams" Only
(Remember for Internals the Question Paper is set by your respective teachers).
Questions may be repeated, just to show students how VTU can frame Questions.
- ADMIN
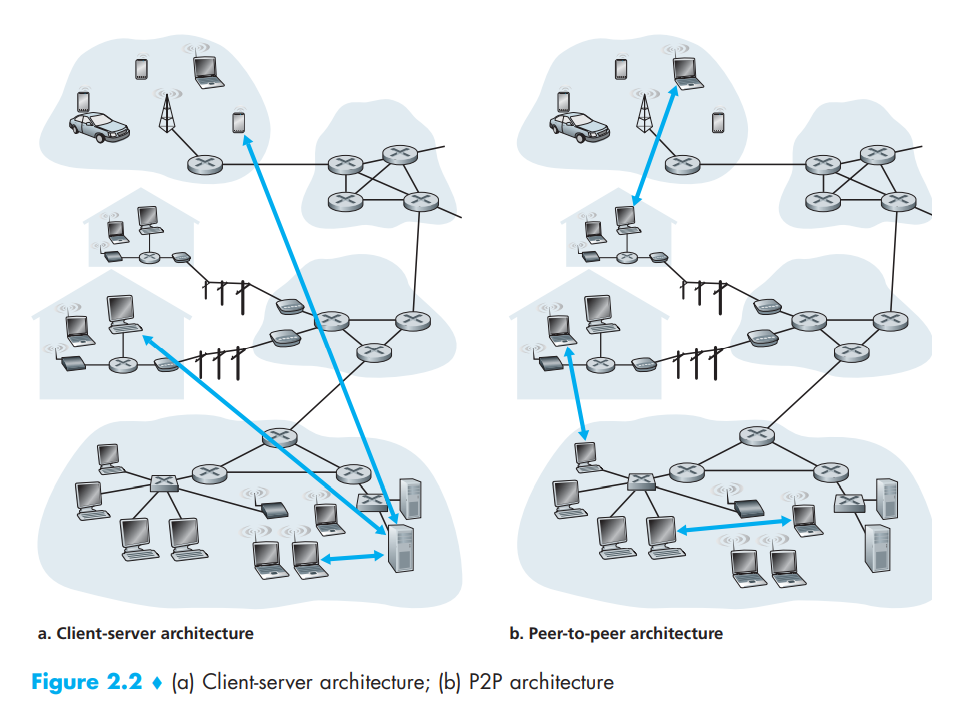
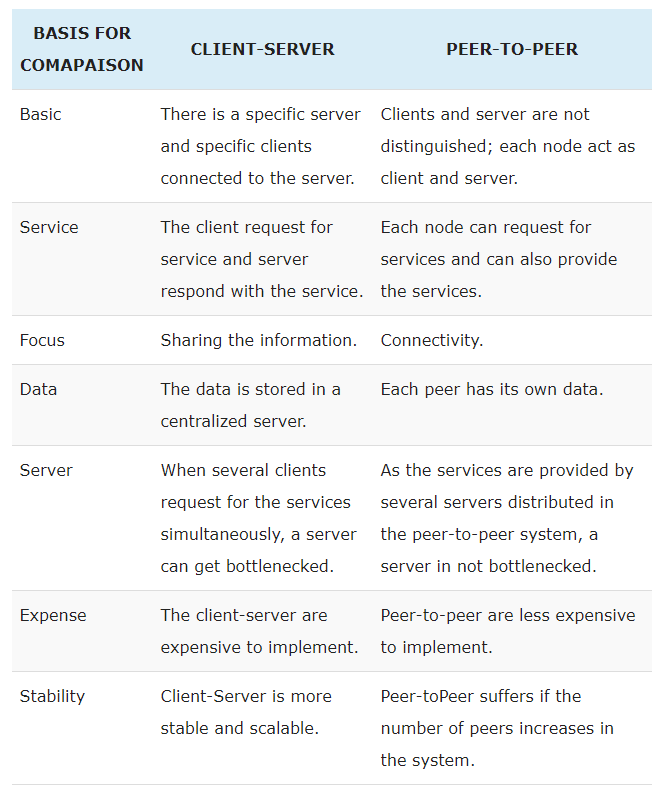
In a client-server architecture, there is an always-on host, called the server, which services requests from many other hosts, called clients. A classic example is the Web application for which an always-on Web server services requests from browsers running on client hosts. When a Web server receives a request for an object from a client host, it responds by sending the requested object to the client host. Note that with the client-server architecture, clients do not directly communicate with each other; for example, in the Web application, two browsers do not directly communicate. Another characteristic of the client-server architecture is that the server has a fixed, well-known address, called an IP address. Because the server has a fixed, well-known address, and because the server is always on, a client can always contact the server by sending a packet to the server's IP address. Some of the better-known applications with a client-server architecture include the Web, FTP, Telnet, and e-mail.
In a P2P architecture, there is minimal (or no) reliance on dedicated servers in data centers. Instead the application exploits direct communication between pairs of intermittently connected hosts, called peers. The peers are not owned by the service provider, but are instead desktops and laptops controlled by users, with most of the peers residing in homes, universities, and offices. Because the peers communicate without passing through a dedicated server, the architecture is called peer-to-peer. Many of today's most popular and traffic-intensive applications are based on P2P architectures. These applications include file sharing (e.g., BitTorrent), peer-assisted download acceleration (e.g., Xunlei), Internet Telephony (e.g., Skype), and IPTV (e.g., Kankan and PPstream). The P2P architecture is illustrated in the below Figure. We mention that some applications have hybrid architectures, combining both client-server and P2P elements. For example, for many instant messaging applications, servers are used to track the IP addresses of users, but user-to-user messages are sent directly between user hosts (without passing through intermediate servers).
HTTP with Non-Persistent Connections:
Let's walk through the steps of transferring a Web page from server to client for the case of non-persistent connections. Let's suppose the page consists of a base HTML file and 10 JPEG images, and that all 11 of these objects reside on the same server.
Further suppose the URL for the base HTML file is
http://www.someSchool.edu/someDepartment/home.index
Here is what happens:
i. The HTTP client process initiates a TCP connection to the server www.someSchool.edu on port number 80, which is the default port number for HTTP. Associated with the TCP connection, there will be a socket at the client and a socket at the server.
ii. The HTTP client sends an HTTP request message to the server via its socket. The request message includes the path name /someDepartment/home.index.
iii. The HTTP server process receives the request message via its socket, retrieves the object /someDepartment/home.index from its storage (RAM or disk), encapsulates the object in an HTTP response message, and sends the response message to the client via its socket.
iv. The HTTP server process tells TCP to close the TCP connection. (But TCP doesn't actually terminate the connection until it knows for sure that the client has received the response message intact.)
v. The HTTP client receives the response message. The TCP connection terminates. The message indicates that the encapsulated object is an HTML file. The client extracts the file from the response message, examines the HTML file, and finds references to the 10 JPEG objects.
vi. The first four steps are then repeated for each of the referenced JPEG objects.
As the browser receives the Web page, it displays the page to the user. Two different browsers may interpret (that is, display to the user) a Web page in somewhat different ways. HTTP has nothing to do with how a Web page is interpreted by a client. The HTTP specifications ([RFC 1945] and [RFC 2616]) define only the communication protocol between the client HTTP program and the server HTTP program.
The steps above illustrate the use of non-persistent connections, where each TCP connection is closed after the server sends the object-the connection does not persist for other objects. Note that each TCP connection transports exactly one request message and one response message. Thus, in this example, when a user requests the Web page, 11 TCP connections are generated.
In the steps described above, we were intentionally vague about whether the client obtains the 10 JPEGs over 10 serial TCP connections, or whether some of the JPEGs are obtained over parallel TCP connections. Indeed, users can configure modern browsers to control the degree of parallelism. In their default modes, most browsers open 5 to 10 parallel TCP connections, and each of these connections handles one request-response transaction. If the user prefers, the maximum number of parallel connections can be set to one, in which case the 10 connections are established serially.
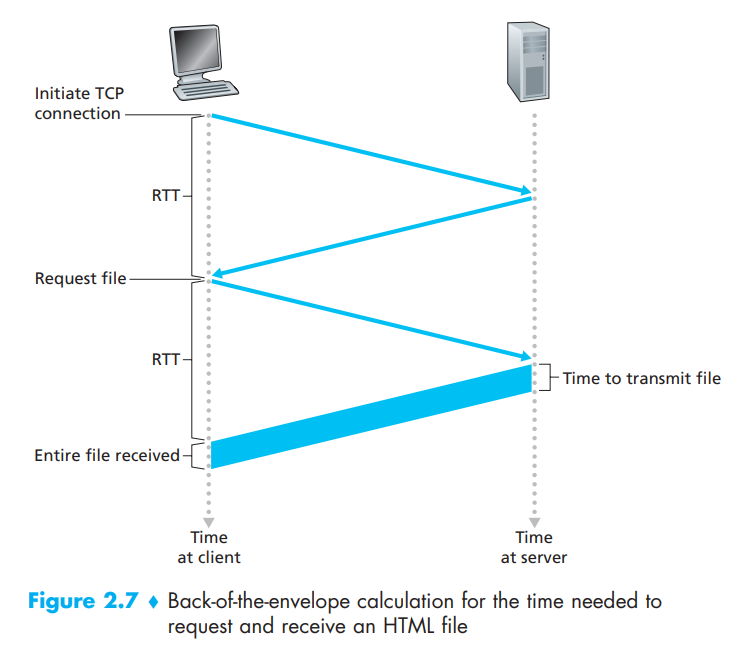
Before continuing, let's do a back-of-the-envelope calculation to estimate
the amount of time that elapses from when a client requests the base HTML
file until the entire file is received by the client. To this end, we
define the round-trip time (RTT
), which is the time it
takes for a small packet to travel from client to server and then back to
the client. The RTT includes packet-propagation delays, packet queuing
delays in intermediate routers and switches, and packet-processing delays.
Now consider what happens when a user clicks on a hyperlink. As shown in
below Figure, this causes the browser to initiate a TCP connection between
the browser and the Web server; this involves a "three-way handshake"-the
client sends a small TCP segment to the server, the server acknowledges and
responds with a small TCP segment, and, finally, the client acknowledges
back to the server. The first two parts of the three-way handshake take one
RTT. After completing the first two parts of the handshake, the client
sends the HTTP request message combined with the third part of the
three-way handshake (the acknowledgment) into the TCP connection. Once the
request message arrives at the server, the server sends the HTML file into
the TCP connection. This HTTP request/response eats up another RTT. Thus,
roughly, the total response time is two RTTs plus the transmission time at
the server of the HTML file.
HTTP with Persistent Connections:
Non-persistent connections have some shortcomings. First, a brand-new connection must be established and maintained for each requested object. For each of these connections, TCP buffers must be allocated and TCP variables must be kept in both the client and server. This can place a significant burden on the Web server, which may be serving requests from hundreds of different clients simultaneously. Second, as we just described, each object suffers a delivery delay of two RTTs-one RTT to establish the TCP connection and one RTT to request and receive an object.
With persistent connections, the server leaves the TCP connection open after sending a response. Subsequent requests and responses between the same client and server can be sent over the same connection. In particular, an entire Web page (in the example above, the base HTML file and the 10 images) can be sent over a single persistent TCP connection. Moreover, multiple Web pages residing on the same server can be sent from the server to the same client over a single persistent TCP connection. These requests for objects can be made back-to-back, without waiting for replies to pending requests (pipelining). Typically, the HTTP server closes a connection when it isn't used for a certain time (a configurable timeout interval). When the server receives the back-to-back requests, it sends the objects back-to-back. The default mode of HTTP uses persistent connections with pipelining.
There are two ways to identify a host-by a hostname and by an IP address.
People prefer the more mnemonic hostname identifier, while routers prefer
fixed-length, hierarchically structured IP addresses. In order to reconcile
these preferences, we need a directory service that translates hostnames to
IP addresses. This is the main task of the Internet's domain name system
(DNS). The DNS is (1)
a distributed database implemented in a hierarchy of DNS servers
, and (2)
an application-layer protocol that allows hosts to query the
distributed database.
The DNS servers are often UNIX machines running the Berkeley Internet Name
Domain (BIND) software [BIND 2012]. The DNS protocol runs over UDP and uses
port 53.
DNS is commonly employed by other application-layer protocols-including HTTP, SMTP, and FTP-to translate user-supplied hostnames to IP addresses.
DNS provides a few other important services in addition to translating hostnames to IP addresses:
i. Host aliasing:
A host with a complicated hostname can
have one or more alias names. For example, a hostname such as
relay1.west-coast.enterprise.com could have, say, two aliases such as
enterprise.com and www.enterprise.com. In this case, the hostname
relay1.westcoast.enterprise.com is said to be a canonical hostname. Alias
hostnames, when present, are typically more mnemonic than canonical
hostnames. DNS can be invoked by an application to obtain the canonical
hostname for a supplied alias hostname as well as the IP address of the
host.
ii. Mail server aliasing:
For obvious reasons, it is
highly desirable that e-mail addresses be mnemonic. For example, if Bob has
an account with Hotmail, Bob's e-mail address might be as simple as
bob@hotmail.com. However, the hostname of the Hotmail mail server is more
complicated and much less mnemonic than simply hotmail.com (for example,
the canonical hostname might be something like
relay1.west-coast.hotmail.com). DNS can be invoked by a mail application to
obtain the canonical hostname for a supplied alias hostname as well as the
IP address of the host. In fact, the MX record permits a company's mail
server and Web server to have identical (aliased) hostnames; for example, a
company's Web server and mail server can both be called enterprise.com.
iii. Load distribution:
DNS is also used to perform load
distribution among replicated servers, such as replicated Web servers. Busy
sites, such as cnn.com, are replicated over multiple servers, with each
server running on a different end system and each having a different IP
address. For replicated Web servers, a set of IP addresses is thus
associated with one canonical hostname. The DNS database contains this set
of IP addresses. When clients make a DNS query for a name mapped to a set
of addresses, the server responds with the entire set of IP addresses, but
rotates the ordering of the addresses within each reply. Because a client
typically sends its HTTP request message to the IP address that is listed
first in the set, DNS rotation distributes the traffic among the replicated
servers.
4.1 Socket Programming with TCP:
TCP is a connection-oriented protocol. This means that before the client and server can start to send data to each other, they first need to handshake and establish a TCP connection.
One end of the TCP connection is attached to the client socket and the other end is attached to a server socket. When creating the TCP connection, we associate with it the client socket address (IP address and port number) and the server socket address (IP address and port number). With the TCP connection established, when one side wants to send data to the other side, it just drops the data into the TCP connection via its socket. This is different from, for which the server must attach a destination address to the packet before dropping it into the socket.
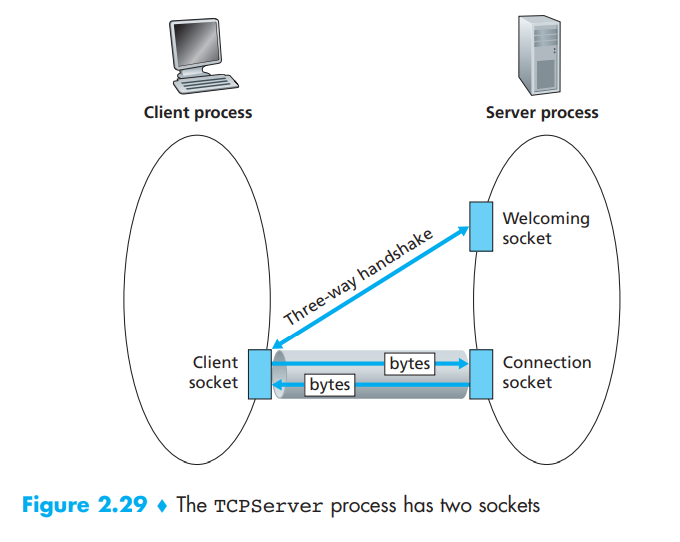
Now let's take a closer look at the interaction of client and server programs in TCP. The client has the job of initiating contact with the server. In order for the server to be able to react to the client's initial contact, the server has to be ready. This implies two things. First, as in the case of UDP, the TCP server must be running as a process before the client attempts to initiate contact. Second, the server program must have a special door-more precisely, a special socket-that welcomes some initial contact from a client process running on an arbitrary host. Using our house/door analogy for a process/socket, we will sometimes refer to the client's initial contact as "knocking on the welcoming door."
With the server process running, the client process can initiate a TCP connection to the server. This is done in the client program by creating a TCP socket. When the client creates its TCP socket, it specifies the address of the welcoming socket in the server, namely, the IP address of the server host and the port number of the socket. After creating its socket, the client initiates a three-way handshake and establishes a TCP connection with the server. The three-way handshake, which takes place within the transport layer, is completely invisible to the client and server programs.
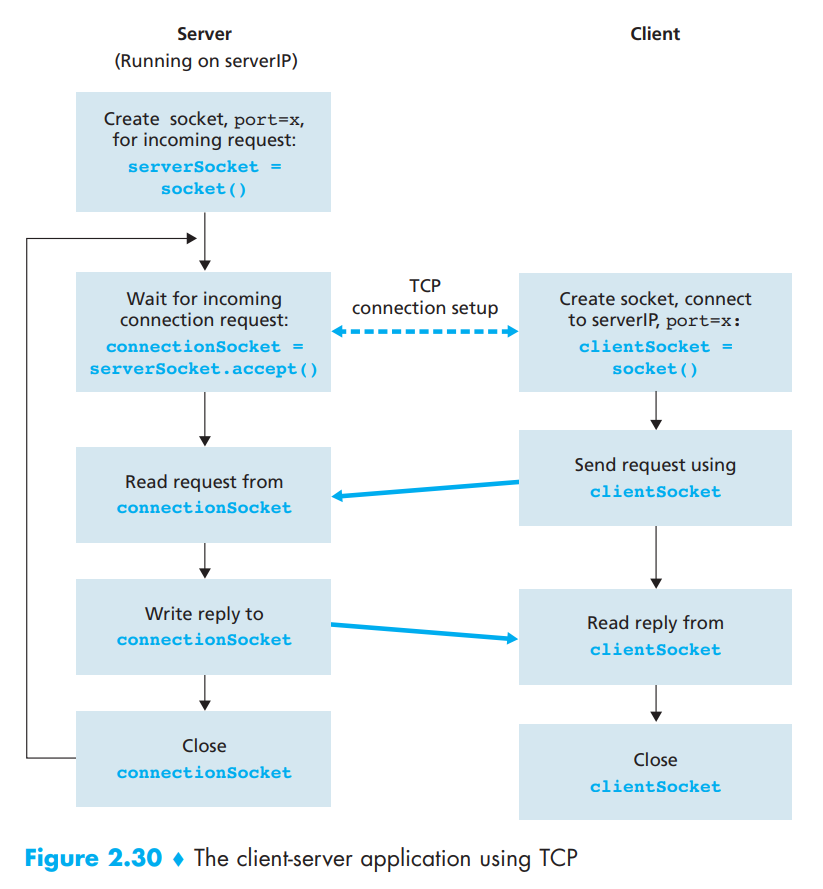
During the three-way handshake, the client process knocks on the welcoming door of the server process. When the server "hears" the knocking, it creates a new door-more precisely, a new socket that is dedicated to that particular client. In our example below, the welcoming door is a TCP socket object that we call serverSocket; the newly created socket dedicated to the client making the connection is called connectionSocket. Students who are encountering TCP sockets for the first time sometimes confuse the welcoming socket (which is the initial point of contact for all clients wanting to communicate with the server), and each newly created server-side connection socket that is subsequently created for communicating with each client.
From the application's perspective, the client's socket and the server's connection socket are directly connected by a pipe. As shown in below Figure, the client process can send arbitrary bytes into its socket, and TCP guarantees that the server process will receive (through the connection socket) each byte in the order sent. TCP thus provides a reliable service between the client and server processes. Furthermore, just as people can go in and out the same door, the client process not only sends bytes into but also receives bytes from its socket; similarly, the server process not only receives bytes from but also sends bytes into its connection socket.
We use the same simple client-server application to demonstrate socket programming with TCP: The client sends one line of data to the server, the server capitalizes the line and sends it back to the client. Figure 2.30 highlights the main socket-related activity of the client and server that communicate over the TCP transport service.
TCPClient.py
Here is the code for the client side of the application:
from socket import *
serverName = 'servername'
serverPort = 12000
clientSocket = socket(AF_INET, SOCK_STREAM)
clientSocket.connect((serverName,serverPort))
sentence = raw_input('Input lowercase sentence:')
clientSocket.send(sentence)
modifiedSentence = clientSocket.recv(1024)
print 'From Server:', modifiedSentence
clientSocket.close()
Let's now take a look at the various lines in the code that differ significantly from the UDP implementation. The first such line is the creation of the client socket.
clientSocket = socket(AF_INET, SOCK_STREAM)
This line creates the client's socket, called clientSocket. The first parameter again indicates that the underlying network is using IPv4. The second parameter indicates that the socket is of type SOCK_STREAM, which means it is a TCP socket (rather than a UDP socket). Note that we are again not specifying the port number of the client socket when we create it; we are instead letting the operating system do this for us. Now the next line of code is very different from what we saw in UDPClient:
clientSocket.connect((serverName,serverPort))
Recall that before the client can send data to the server (or vice versa) using a TCP socket, a TCP connection must first be established between the client and server. The above line initiates the TCP connection between the client and server. The parameter of the connect() method is the address of the server side of the connection. After this line of code is executed, the three-way handshake is performed and a TCP connection is established between the client and server.
sentence = raw_input('Input lowercase sentence:')
As with UDPClient, the above obtains a sentence from the user. The string sentence continues to gather characters until the user ends the line by typing a carriage return. The next line of code is also very different from UDPClient:
clientSocket.send(sentence)
The above line sends the string sentence through the client's socket and into the TCP connection. Note that the program does not explicitly create a packet and attach the destination address to the packet, as was the case with UDP sockets. Instead the client program simply drops the bytes in the string sentence into the TCP connection. The client then waits to receive bytes from the server.
modifiedSentence = clientSocket.recv(2048)
When characters arrive from the server, they get placed into the string modifiedSentence. Characters continue to accumulate in modifiedSentence until the line ends with a carriage return character. After printing the capitalized sentence, we close the client's socket:
clientSocket.close()
This last line closes the socket and, hence, closes the TCP connection between the client and the server. It causes TCP in the client to send a TCP message to TCP in the server
TCPServer.py
Now let's take a look at the server program
from socket import *
serverPort = 12000
serverSocket = socket(AF_INET,SOCK_STREAM)
serverSocket.bind(('',serverPort))
serverSocket.listen(1)
print 'The server is ready to receive'
while 1:
connectionSocket, addr = serverSocket.accept()
sentence = connectionSocket.recv(1024)
capitalizedSentence = sentence.upper()
connectionSocket.send(capitalizedSentence)
connectionSocket.close()
Let's now take a look at the lines that differ significantly from UDPServer and TCPClient. As with TCPClient, the server creates a TCP socket with:
serverSocket=socket(AF_INET,SOCK_STREAM)
Similar to UDPServer, we associate the server port number, serverPort, with this socket:
serverSocket.bind(('',serverPort))
But with TCP, serverSocket will be our welcoming socket. After establishing this welcoming door, we will wait and listen for some client to knock on the door:
serverSocket.listen(1)
This line has the server listen for TCP connection requests from the client. The parameter specifies the maximum number of queued connections (at least 1).
connectionSocket, addr = serverSocket.accept()
When a client knocks on this door, the program invokes the accept() method for serverSocket, which creates a new socket in the server, called connectionSocket, dedicated to this particular client. The client and server then complete the handshaking, creating a TCP connection between the client's clientSocket and the server's connectionSocket. With the TCP connection established, the client and server can now send bytes to each other over the connection. With TCP, all bytes sent from one side not are not only guaranteed to arrive at the other side but also guaranteed arrive in order.
connectionSocket.close()
In this program, after sending the modified sentence to the client, we close the connection socket. But since serverSocket remains open, another client can now knock on the door and send the server a sentence to modify.
A Web cache-also called a proxy server-is a network entity that satisfies HTTP requests on the behalf of an origin Web server. The Web cache has its own disk storage and keeps copies of recently requested objects in this storage. As shown in the below Figure, a user's browser can be configured so that all of the user's HTTP requests are first directed to the Web cache. Once a browser is configured, each browser request for an object is first directed to the Web cache. As an example, suppose a browser is requesting the object http://www.someschool.edu/campus.gif. Here is what happens:
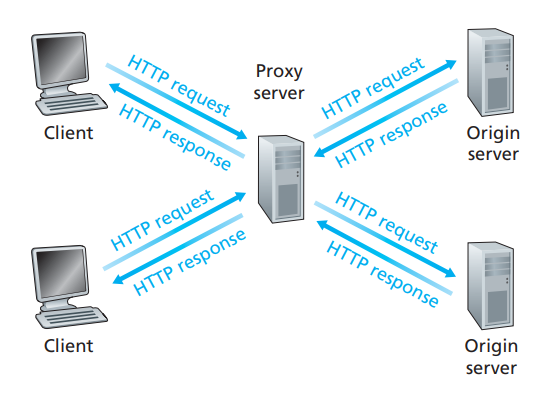
Fig 4.1: Clients requesting objects through a Web cache
i. The browser establishes a TCP connection to the Web cache and sends an HTTP request for the object to the Web cache.
ii. The Web cache checks to see if it has a copy of the object stored locally. If it does, the Web cache returns the object within an HTTP response message to the client browser.
iii. If the Web cache does not have the object, the Web cache opens a TCP connection to the origin server, that is, to www.someschool.edu. The Web cache then sends an HTTP request for the object into the cache-to-server TCP connection. After receiving this request, the origin server sends the object within an HTTP response to the Web cache.
iv. When the Web cache receives the object, it stores a copy in its local storage and sends a copy, within an HTTP response message, to the client browser (over the existing TCP connection between the client browser and the Web cache).
Note that a cache is both a server and a client at the same time. When it receives requests from and sends responses to a browser, it is a server. When it sends requests to and receives responses from an origin server, it is a client.
Typically a Web cache is purchased and installed by an ISP. For example, a university might install a cache on its campus network and configure all of the campus browsers to point to the cache. Or a major residential ISP (such as AOL) might install one or more caches in its network and preconfigure its shipped browsers to point to the installed caches.
Web caching has seen deployment in the Internet for two reasons. First, a Web cache can substantially reduce the response time for a client request, particularly if the bottleneck bandwidth between the client and the origin server is much less than the bottleneck bandwidth between the client and the cache. If there is a high-speed connection between the client and the cache, as there often is, and if the cache has the requested object, then the cache will be able to deliver the object rapidly to the client. Second, as we will soon illustrate with an example, Web caches can substantially reduce traffic on an institution's access link to the Internet. By reducing traffic, the institution (for example, a company or a university) does not have to upgrade bandwidth as quickly, thereby reducing costs. Furthermore, Web caches can substantially reduce Web traffic in the Internet as a whole, thereby improving performance for all applications.
Below Page NAVIGATION Links are Provided...
All the Questions on Question Bank Is SOLVED