 MENU
MENU


NOTE!
Click on MENU to Browse between Subjects...17CS53 - DATABASE MANAGEMENT SYSTEM
Answer Script for Module 2
Solved Previous Year Question Paper
CBCS SCHEME
DATABASE MANAGEMENT SYSTEM
DBMS
[As per Choice Based Credit System (CBCS) scheme]
(Effective from the academic year 2019 -2020)
SEMESTER - V
Subject Code 17CS53
IA Marks 40
Number of Lecture Hours/Week 04
Exam Marks 60
These Questions are being framed for helping the students in the "FINAL Exams" Only
(Remember for Internals the Question Paper is set by your respective teachers).
Questions may be repeated, just to show students how VTU can frame Questions.
- ADMIN
The characteristics of relations are as follows:
1.1 Ordering of Tuples in a Relation:
A relation is defined as a set of tuples. Mathematically, elements of a set have no order among them; hence, tuples in a relation do not have any particular order.
In other words, a relation is not sensitive to the ordering of tuples. However, in a file, records are physically stored on disk (or in memory), so there always is an order among the records.
This ordering indicates first, second, ith, and last records in the file. Similarly, when we display a relation as a table, the rows are displayed in a certain order.
1.2 Ordering of Values within a Tuple and an Alternative Definition of
a Relation:
According to the preceding definition of a relation, an n-tuple is an ordered list of n values, so the ordering of values in a tuple-and hence of attributes in a relation schema-is important.
However, at a more abstract level, the order of attributes and their values is not that important as long as the correspondence between attributes and values is maintained.
1.3 Values and NULLs in the Tuples:
Each value in a tuple is an atomic value; that is, it is not divisible into components within the framework of the basic relational model.
Hence, composite and multivalued attributes are not allowed. This model is
sometimes called the flat relational model
.
Much of the theory behind the relational model was developed with this assumption in mind, which is called the first normal form assumption.
Hence, multivalued attributes must be represented by separate relations, and composite attributes are represented only by their simple component attributes in the basic relational model.
1.4 Interpretation (Meaning) of a Relation:
Each relation can be viewed as a predicate and each tuple in that relation can be viewed as an assertion for which that predicate is satisfied (i.e., has value true) for the combination of values in it. In other words, each tuple represents a fact.
In general, a student entity has a Name, Ssn, Home_phone, Address, Office_phone, Age, and Gpa. Each tuple in the relation can then be interpreted as a fact or a particular instance of the assertion.
There are three basic operations that can change the states of relations in the database: Insert, Delete, and Update (or Modify).
They insert new data, delete old data, or modify existing data records, respectively.
i. Insert
is used to insert one or more new tuples in a
relation,
ii. Delete
is used to delete tuples, and
iii. Update
(or Modify) is used to change the values of
some attributes in existing tuples.
Whenever these operations are applied, the integrity constraints specified on the relational database schema should not be violated.
2.1 The Insert Operation
The Insert operation provides a list of attribute values for a new tuple t that is to be inserted into a relation R. Insert can violate any of the four types of constraints. Domain constraints can be violated if an attribute value is given that does not appear in the corresponding domain or is not of the appropriate data type.
Key constraints can be violated if a key value in the new tuple t already exists in another tuple in the relation r(R). Entity integrity can be violated if any part of the primary key of the new tuple t is NULL. Referential integrity can be violated if the value of any foreign key in t refers to a tuple that does not exist in the referenced relation. Here are some examples to illustrate this discussion.
i. Operation: Insert into EMPLOYEE. Result: This insertion violates the entity integrity constraint (NULL for the primary key Ssn), so it is rejected.
ii. Operation: Insert into EMPLOYEE. Result: This insertion violates the key constraint because another tuple with the same Ssn value already exists in the EMPLOYEE relation, and so it is rejected.
iii. Operation: Insert into EMPLOYEE. Result: This insertion violates the referential integrity constraint specified on Dno in EMPLOYEE because no corresponding referenced tuple exists in DEPARTMENT with Dnumber = 7.
2.2 The Delete Operation
The Delete operation can violate only referential integrity. This occurs if the tuple being deleted is referenced by foreign keys from other tuples in the database. To specify deletion, a condition on the attributes of the relation selects the tuple (or tuples) to be deleted. Here are some examples.
i. Operation: Delete the WORKS_ON tuple with Essn = '999887777' and Pno = 10. Result: This deletion is acceptable and deletes exactly one tuple.
ii. Operation: Delete the EMPLOYEE tuple with Ssn = '999887777'. Result: This deletion is not acceptable, because there are tuples in WORKS_ON that refer to this tuple. Hence, if the tuple in EMPLOYEE is deleted, referential integrity violations will result.
iii. Operation: Delete the EMPLOYEE tuple with Ssn = '333445555'. Result: This deletion will result in even worse referential integrity violations, because the tuple involved is referenced by tuples from the EMPLOYEE, DEPARTMENT, WORKS_ON, and DEPENDENT relations.
2.3 The Update Operation
The Update (or Modify) operation is used to change the values of one or more attributes in a tuple (or tuples) of some relation R. It is necessary to specify a condition on the attributes of the relation to select the tuple (or tuples) to be modified. Here are some examples.
i. Operation: Update the salary of the EMPLOYEE tuple with Ssn = '999887777' to 28000. Result: Acceptable.
ii. Operation: Update the Dno of the EMPLOYEE tuple with Ssn = '999887777' to 1. Result: Acceptable.
iii. Operation: Update the Dno of the EMPLOYEE tuple with Ssn = '999887777' to 7. Result: Unacceptable, because it violates referential integrity.
iv. Operation: Update the Ssn of the EMPLOYEE tuple with Ssn = '999887777' to '987654321'. Result: Unacceptable, because it violates primary key constraint by repeating a value that already exists as a primary key in another tuple; it violates referential integrity constraints because there are other relations that refer to the existing value of Ssn.
Step 1:
For each regular (strong) entity type
E in the ER schema,
create a relation R that includes all the simple attributes of E.
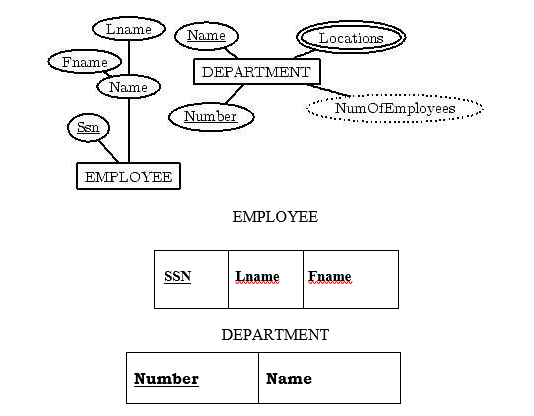
Step 2
: For each weak entity type
W in the ER schema with owner
entity type E, create a relation R, and include all simple attributes (or
simple components of composite attributes) of W as attributes. In addition,
include as foreign key attributes of R the primary key attribute(s) of the
relation(s) that correspond to the owner entity type(s).
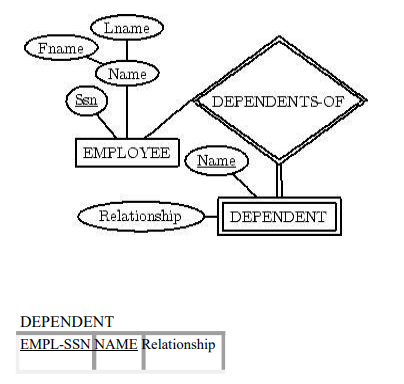
Step 3:
For each binary 1:1 relationship type
R in the ER schema,
identify the relations S and T that correspond to the entity types
participating in R. Choose one of the relations, say S, and include the
primary key of T as a foreign key in S. Include all the simple attributes
of R as attributes of S.
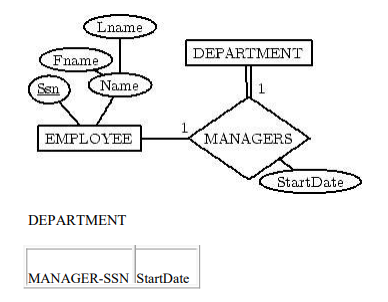
Step 4:
For each regular binary 1:N relationship type
R identify
the relation (N) relation S. Include the primary key of T as a foreign key
of S. Simple attributes of R map to attributes of S.
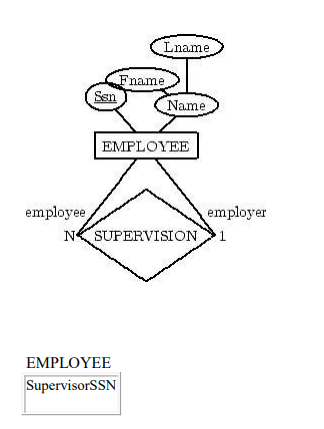
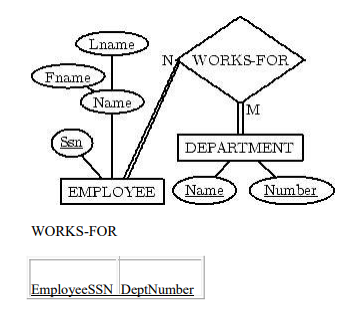
Step 5:
For each binary M:N relationship type
R, create a relation
S. Include the primary keys of participant relations as foreign keys in S.
Their combination will be the primary key for S. Simple attributes of R
become attributes of S.
Step 6:
For each multi-valued attribute A
, create a new relation
R. This relation will include an attribute corresponding to A, plus the
primary key K of the parent relation (entity type or relationship type) as
a foreign key in R. The primary key of R is the combination of A and K.
The basic constraints that can be specified in SQL as part of table creation. These include key and referential integrity constraints, restrictions on attribute domains and NULLs, and constraints on individual tuples within a relation using the CHECK clause.
4.1 Specifying Attribute Constraints and Attribute Defaults:
Because SQL allows NULLs as attribute values, a constraint NOT NULL may be specified if NULL is not permitted for a particular attribute. This is always implicitly specified for the attributes that are part of the primary key of each relation, but it can be specified for any other attributes whose values are required not to be NULL.
It is also possible to define a default value for an attribute by appending the clause DEFAULT to an attribute definition. The default value is included in any new tuple if an explicit value is not provided for that attribute.
Figure 4.1 illustrates an example of specifying a default manager for a new department and a default department for a new employee. If no default clause is specified, the default default value is NULL for attributes that do not have the NOT NULL constraint.
Another type of constraint can restrict attribute or domain values using the CHECK clause following an attribute or domain definition.6 For example, suppose that department numbers are restricted to integer numbers between 1 and 20; then, we can change the attribute declaration of Dnumber in the DEPARTMENT table (see Figure 6.1) to the following:
Dnumber INT NOT NULL CHECK (Dnumber > 0 AND Dnumber < 21);
The CHECK clause can also be used in conjunction with the CREATE DOMAIN statement. For example, we can write the following statement:
CREATE DOMAIN D_NUM AS INTEGER CHECK (D_NUM > 0 AND D_NUM < 21);
4.2 Specifying Key and Referential Integrity Constraints
Because keys and referential integrity constraints are very important, there are special clauses within the CREATE TABLE statement to specify them. Some examples to illustrate the specification of keys and referential integrity.
The PRIMARY KEY
clause specifies one or more attributes
that make up the primary key of a relation. If a primary key has a single
attribute, the clause can follow the attribute directly. For example, the
primary key of DEPARTMENT can be specified as follows
Dnumber INT PRIMARY KEY
The UNIQUE
clause specifies alternate (unique) keys, also
known as candidate keys as illustrated in the DEPARTMENT and PROJECT table
declarations. The UNIQUE clause
can also be specified
directly for a unique key if it is a single attribute, as in the following
example:
Dname VARCHAR(15) UNIQUE
A referential integrity constraint can be violated when tuples are inserted or deleted, or when a foreign key or primary key attribute value is updated. The default action that SQL takes for an integrity violation is to reject the update operation that will cause a violation, which is known as the RESTRICT option.
However, the schema designer can specify an alternative action to be taken
by attaching a referential triggered action
clause to any
foreign key constraint.
4.3 Giving Names to Constraints
Figure 4.1 also illustrates how a constraint may be given a constraint name, following the keyword CONSTRAINT. The names of all constraints within a particular schema must be unique.
A constraint name is used to identify a particular constraint in case the constraint must be dropped later and replaced with another constraint.
Giving names to constraints is optional. It is also possible to temporarily defer a constraint until the end of a transaction.
4.4 Specifying Constraints on Tuples Using CHECK
In addition to key and referential integrity constraints, which are specified by special keywords, other table constraints can be specified through additional CHECK clauses at the end of a CREATE TABLE statement.
These can be called row-based constraints because they apply to each row individually and are checked whenever a row is inserted or modified.
CHECK (Dept_create_date <= Mgr_start_date);
The CHECK clause can also be used to specify more general constraints using the CREATE ASSERTION statement of SQL.

Fig 4.1
The basic data types available for attributes include numeric, character string, bit string, Boolean, date, and time.
i. Numeric data
types include integer numbers of various
sizes (INTEGER or INT, and SMALLINT) and floating-point (real) numbers of
various precision (FLOAT or REAL, and DOUBLE PRECISION). Formatted numbers
can be declared by using DECIMAL(i, j)-or DEC(i, j) or NUMERIC(i, j)-where
i, the precision, is the total number of decimal digits and j, the scale,
is the number of digits after the decimal point. The default for scale is
zero, and the default for precision is implementation-defined.
ii. Character-string
data types are either fixed
length-CHAR(n) or CHARACTER(n), where n is the number of characters-or
varying length- VARCHAR(n) or CHAR VARYING(n) or CHARACTER VARYING(n),
where n is the maximum number of characters. When specifying a literal
string value, it is placed between single quotation marks (apostrophes),
and it is case sensitive (a distinction is made between uppercase and
lowercase).
iii. Bit-string
data types are either of fixed length
n-BIT(n)-or varying length- BIT VARYING(n), where n is the maximum number
of bits. The default for n, the length of a character string or bit string,
is 1. Literal bit strings are placed between single quotes but preceded by
a B to distinguish them from character strings; for example, B'10101'.
iv. A Boolean
data type has the traditional values of TRUE
or FALSE. In SQL, because of the presence of NULL values, a three-valued
logic is used, so a third possible value for a Boolean data type is
UNKNOWN.
v. The DATE
data type has ten positions, and its
components are YEAR, MONTH, and DAY in the form YYYY-MM-DD. The TIME data
type has at least eight positions, with the components HOUR, MINUTE, and
SECOND in the form HH:MM:SS. Only valid dates and times should be allowed
by the SQL implementation. This implies that months should be between 1 and
12 and days must be between 01 and 31; furthermore, a day should be a valid
day for the corresponding month. The < (less than) comparison can be
used with dates or times-an earlier date is considered to be smaller than a
later date, and similarly with time. Literal values are represented by
single-quoted strings preceded by the keyword DATE or TIME.
Below Page NAVIGATION Links are Provided...
All the Questions on Question Bank Is SOLVED
Follow our Instagram Page:
FutureVisionBIE
https://www.instagram.com/futurevisionbie/
Message: I'm Unable to Reply to all your Emails
so, You can DM me on the Instagram Page & any other Queries.