 MENU
MENU


NOTE!
Click on MENU to Browse between Subjects...17CS53 - DATABASE MANAGEMENT SYSTEM
Answer Script for Module 3
Solved Previous Year Question Paper
CBCS SCHEME
DATABASE MANAGEMENT SYSTEM
DBMS
[As per Choice Based Credit System (CBCS) scheme]
(Effective from the academic year 2019 -2020)
SEMESTER - V
Subject Code 17CS53
IA Marks 40
Number of Lecture Hours/Week 04
Exam Marks 60
These Questions are being framed for helping the students in the "FINAL Exams" Only
(Remember for Internals the Question Paper is set by your respective teachers).
Questions may be repeated, just to show students how VTU can frame Questions.
- ADMIN
1
SELECT SNAME FROM SUPPLIER WHERE SNO IN( SELECT SNO FROM SHIPMENT WHERE PNO='P2');
2.
SELECT S.SNAME FROM SUPPLIER S,SHIPMENT SP WHERE S.SNO=SP.SNO AND PNO IN(SELECT PNO FROM SHIPMENT WHERE SP.SNO<>'S2');
3.
SELECT PNO FROM SHIPMENT DROUP BY PNO HAVING COUNT(*) >1;
4.
SELECT PNO,MAX(QUANTITY),MIN(QUANTITY) FROM SHIPMENT;
5.
SELECT SNO FROM SUPPLIER WHERE STATUS < (SELECT MAX(SATUS) FROM SUPPLIER);
2.1 Definition
A stored procedure
is a program that is executed through a
single SQL statement that can be locally executed and completed within the
process space of the database server. The results can be packaged into one
big result and returned to the application, or the application logic can be
performed directly at the server, without having to transmit the results to
the client at all.
Stored procedures
are also beneficial for software engineering reasons. Once a stored
procedure is registered with the database server, different users can
re-use the stored procedure, eliminating duplication of efforts in writing
SQL queries or application logic, and making code maintenance easy.
2.2 Creating a Simple Stored Procedure
We see that stored procedures must have a name; this stored procedure has the name 'ShowNumberOfOrders.' Otherwise, it just contains an SQL statement that is precompiled and stored at the server.

Fig 2.1: A Stored Procedure in SQL
Stored procedures can also have parameters. These parameters have to be valid SQL types, and have one of three different modes: IN, OUT, or INOUT. IN parameters are arguments to' the stored procedure. OUT parameters are returned from the stored procedure; it assigns values to all OUT parameters that the user can process. INOUT parameters combine the properties of IN and OUT parameters: They contain values to be passed to the stored procedures, and the stored procedure can set their values as return values. Stored procedures enforce strict type conformance: If a parameter is of type INTEGER, it cannot be called with an argument of type VARCHAR.
Let us look at an example of a stored procedure with arguments. The stored procedure shown in Figure 2.1 has two arguments: book_isbn and addedQty. It updates the available number of copies of a book with the quantity from a new shipment.

Fig 2.2: A Stored Procedure with Arguments
Stored procedures do not have to be written in SQL; they can be written in any host language. As an example, the stored procedure shown in Figure 0.10 is a Java function that is dynamically executed by the database server whenever it is called by the client.
2.3 Calling Stored Procedures
Stored procedures can be called in interactive SQL with the CALL statement:

Fig 2.3: A Stored Procedure in Java
CALL storedProcedureName(argumentl, argument2, ... , argumentN);
In Embedded SQL, the arguments to a stored procedure are usually variables in the host language. For example, the stored procedure AddInventory would be called as follows:

In this section, we provide some perspective on the three-tier architecture by discussing single-tier and client-server architectures, the predecessors of the three-tier architecture.
Initially, data-intensive applications were combined into a single tier,
including the DBMS, application logic, and user interface, a" illustrated
in Figure 3.1. The application typically ran on a mainframe, and users
accessed it through dumb teT'minals
that could
perform only data input and display. This approach has the benefit of being
easily maintained by a central administrator.
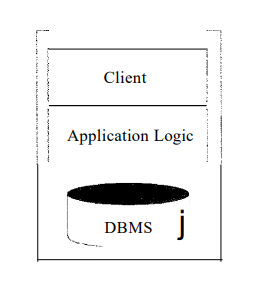
Fig 3.1: A Single-Tier Architecture
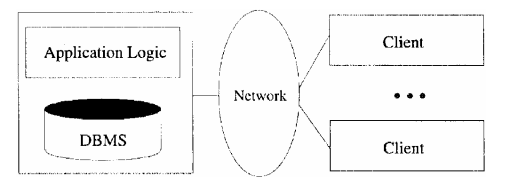
Fig 3.2: A Two-Server Architecture: Thin Clients
Single-tier architectures have an important drawback: Users expect graphical interfaces that require much more computational power than simple dumb terminals. Centralized computation of the graphical displays of such interfaces requires much more computational power than a single server has available, and thus single-tier architectures do not scale to thousands of users. The commoditization of the PC and the availability of cheap client computers led to the development of the two-tier architecture.
Two-tier architectures, often also referred to as; client-server architectures, consist of a client computer and a server computer, which interact through a well-defined protocol. What part of the functionality the client implements, and what part is left to the server, can vary. In the traditional client-server architecture, the client implements just the graphical user interface, and the server. implements both the business logic and the data management; such clients are often called thin clients, and this architecture is illustrated in Figure 3.2.
i)
Nested Queries
Answer:
Some queries require that existing values in the database be fetched and
then used in a comparison condition. Such queries can be conveniently
formulated by using nested queries
, which are complete
select-from-where blocks within another SQL query. That other query is
called the outer query
.
These nested queries can also appear in the WHERE clause or the FROM clause or the SELECT clause or other SQL clauses as needed.
In Q4A, the first nested query selects the project numbers of projects that have an employee with last name 'Smith' involved as manager, whereas the second nested query selects the project numbers of projects that have an employee with last name 'Smith' involved as worker. In the outer query, we use the OR logical connective to retrieve a PROJECT tuple if the PNUMBER value of that tuple is in the result of either nested query.

If a nested query returns a single attribute and a single tuple, the query result will be a single (scalar) value. In such cases, it is permissible to use = instead of IN for the comparison operator. In general, the nested query will return a table (relation), which is a set or multiset of tuples.
SQL allows the use of tuples of values in comparisons by placing them within parentheses. To illustrate this, consider the following query:

ii)
Aggregate functions
Answer:
Aggregate functions are used to summarize information from multiple tuples
into a single-tuple summary. Grouping is used to create subgroups of tuples
before summarization. Grouping and aggregation are required in many
database applications, and we will introduce their use in SQL through
examples. A number of built-in aggregate functions exist: COUNT, SUM, MAX, MIN, and AVG.
The COUNT function returns the number of tuples or values as specified in a query. The functions SUM, MAX, MIN, and AVG can be applied to a set or multiset of numeric values and return, respectively, the sum, maximum value, minimum value, and average (mean) of those values.
These functions can be used in the SELECT clause or in a HAVING clause (which we introduce later). The functions MAX and MIN can also be used with attributes that have nonnumeric domains if the domain values have a total ordering among one another.3 We illustrate the use of these functions with several queries.
Find the sum of the salaries of all employees, the maximum salary, the minimum salary, and the average salary.
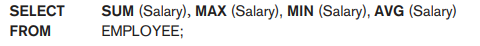
This query returns a single-row summary of all the rows in the EMPLOYEE table. We could use AS to rename the column names in the resulting single-row table; for example
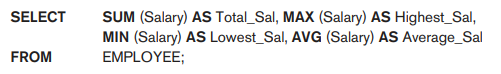
iii)
Triggers
Answer:
The CREATE TRIGGER
, which can be used to specify automatic
actions that the database system will perform when certain events and
conditions occur. This type of functionality is generally referred to as
active databases.
Another important statement in SQL is CREATE TRIGGER. In many cases it is convenient to specify the type of action to be taken when certain events occur and when certain conditions are satisfied. For example, it may be useful to specify a condition that, if violated, causes some user to be informed of the violation.
A manager may want to be informed if an employee's travel expenses exceed a certain limit by receiving a message whenever this occurs. The action that the DBMS must take in this case is to send an appropriate message to that user.
The condition is thus used to monitor the database. Other actions may be specified, such as executing a specific stored procedure or triggering other updates. The CREATE TRIGGER statement is used to implement such actions in SQL.

The trigger is given the name SALARY_VIOLATION, which can be used to remove or deactivate the trigger later. A typical trigger which is regarded as an ECA (Event, Condition, Action) rule has three components:
i. The event(s):
These are usually database update
operations that are explicitly applied to the database. In this example the
events are: inserting a new employee record, changing an employee's salary,
or changing an employee's supervisor. The person who writes the trigger
must make sure that all possible events are accounted for. In some cases,
it may be necessary to write more than one trigger to cover all possible
cases. These events are specified after the keyword BEFORE in our example,
which means that the trigger should be executed before the triggering
operation is executed. An alternative is to use the keyword AFTER, which
specifies that the trigger should be executed after the operation specified
in the event is completed.
ii. The condition
that determines whether the rule action
should be executed: Once the triggering event has occurred, an optional
condition may be evaluated. If no condition is specified, the action will
be executed once the event occurs. If a condition is specified, it is first
evaluated, and only if it evaluates to true will the rule action be
executed. The condition is specified in the WHEN clause of the trigger.
iii. The action
to be taken: The action is usually a
sequence of SQL statements, but it could also be a database transaction or
an external program that will be automatically executed. In this example,
the action is to execute the stored procedure INFORM_SUPERVISOR.
Triggers can be used in various applications, such as maintaining database consistency, monitoring database updates, and updating derived data automatically.
iv)
Views and their updatability
Answer:
A view in SQL terminology is a single table that is derived from other
tables. These other tables can be base tables or previously defined views.
A view
does not necessarily exist in physical form; it is
considered to be a virtual table
, in contrast to base tables
, whose tuples are always physically stored in
the database. This limits the possible update operations that can be
applied to views, but it does not provide any limitations on querying a
view.
The command to specify a view is CREATE VIEW. The view is given a (virtual) table name (or view name), a list of attribute names, and a query to specify the contents of the view. If none of the view attributes results from applying functions or arithmetic operations, we do not have to specify new attribute names for the view, since they would be the same as the names of the attributes of the defining tables in the default case.

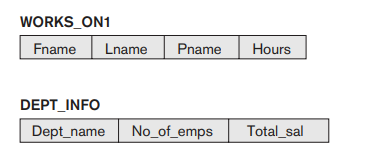
Fig 4.7: Two views specified on the database schema
In V1, we did not specify any new attribute names for the view WORKS_ON1 (although we could have); in this case, WORKS_ON1 inherits the names of the view attributes from the defining tables EMPLOYEE, PROJECT, and WORKS_ON. View V2 explicitly specifies new attribute names for the view DEPT_INFO, using a one-to-one correspondence between the attributes specified in the CREATE VIEW clause and those specified in the SELECT clause of the query that defines the view.
a.
View Implementation, View Update, and Inline Views:
The problem of how a DBMS can efficiently implement a view for efficient querying is complex. Two main approaches have been suggested. One strategy, called query modification, involves modifying or transforming the view query (submitted by the user) into a query on the underlying base tables. For example, the query QV1 would be automatically modified to the following query by the DBMS.

The disadvantage of this approach is that it is inefficient for views defined via complex queries that are time-consuming to execute, especially if multiple view queries are going to be applied to the same view within a short period of time. The second strategy, called view materialization.
A user can always issue a retrieval query against any view. However, issuing an INSERT, DELETE, or UPDATE command on a view table is in many cases not possible. In general, an update on a view defined on a single table without any aggregate functions can be mapped to an update on the underlying base table under certain conditions.
For a view involving joins, an update operation may be mapped to update operations on the underlying base relations in multiple ways. Hence, it is often not possible for the DBMS to determine which of the updates is intended. To illustrate potential problems with updating a view defined on multiple tables, consider the WORKS_ON1 view, and suppose that we issue the command to update the PNAME attribute of 'John Smith' from 'ProductX' to 'ProductY'.

This query can be mapped into several updates on the base relations to give the desired update effect on the view. In addition, some of these updates will create additional side effects that affect the result of other queries. For example, here are two possible updates, (a) and (b), on the base relations corresponding to the view update operation.
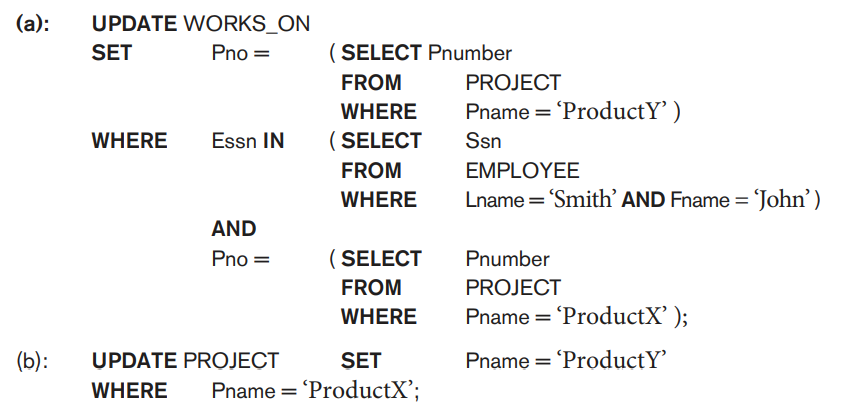
Update (a) relates 'John Smith' to the 'ProductY' PROJECT tuple instead of the 'ProductX' PROJECT tuple and is the most likely desired update. However, (b) would also give the desired update effect on the view, but it accomplishes this by changing the name of the 'ProductX' tuple in the PROJECT relation to 'ProductY'. It is quite unlikely that the user who specified the view update UV1 wants the update to be interpreted as in (b), since it also has the side effect of changing all the view tuples with Pname = 'ProductX'
In summary, we can make the following observations:
A. A view with a single defining table is updatable if the view attributes contain the primary key of the base relation, as well as all attributes with the NOT NULL constraint that do not have default values specified
B. Views defined on multiple tables using joins are generally not updatable.
C. Views defined using grouping and aggregate functions are not updatable.
v)
Schema change statements
Answer:
an overview of the schema evolution commands available in SQL, which can be used to alter a schema by adding or dropping tables, attributes, constraints, and other schema elements. This can be done while the database is operational and does not require recompilation of the database schema. Certain
The DROP Command
The DROP command can be used to drop named schema elements, such as tables, domains, types, or constraints. One can also drop a whole schema if it is no longer needed by using the DROP SCHEMA command. There are two drop behavior options: CASCADE and RESTRICT. For example, to remove the COMPANY database schema and all its tables, domains, and other elements, the CASCADE option is used as follows:
DROP SCHEMA COMPANY CASCADE;
If the RESTRICT option is chosen in place of CASCADE, the schema is dropped only if it has no elements in it; otherwise, the DROP command will not be executed. To use the RESTRICT option, the user must first individually drop each element in the schema, then drop the schema itself.
The ALTER Command
The definition of a base table or of other named schema elements can be changed by using the ALTER command. For base tables, the possible alter table actions include adding or dropping a column (attribute), changing a column definition, and adding or dropping table constraints. For example, to add an attribute for keeping track of jobs of employees to the EMPLOYEE base relation in the COMPANY schema, we can use the command
ALTER TABLE COMPANY.EMPLOYEE ADD COLUMN Job VARCHAR(12);
We must still enter a value for the new attribute Job for each individual EMPLOYEE tuple. This can be done either by specifying a default clause or by using the UPDATE command individually on each tuple (see Section 6.4.3). If no default clause is specified, the new attribute will have NULLs in all the tuples of the relation immediately after the command is executed; hence, the NOT NULL constraint is not allowed in this case.

vi)
Group by and having clause
Answer:
In many cases we want to apply the aggregate functions to subgroups of tuples in a relation, where the subgroups are based on some attribute values. For example, we may want to find the average salary of employees in each department or the number of employees who work on each project. In these cases, we need to partition the relation into non-overlapping subsets (or groups) of tuples. Each group (partition) will consist of the tuples that have the same value of some attribute(s), called the grouping attribute(s). We can then apply the function to each such group independently to produce summary information about each group.
SQL has a GROUP BY clause for this purpose. The GROUP BY clause specifies the grouping attributes, which should also appear in the SELECT clause, so that the value resulting from applying each aggregate function to a group of tuples appears along with the value of the grouping attribute(s).
For each department, retrieve the department number, the number of employees in the department, and their average salary.
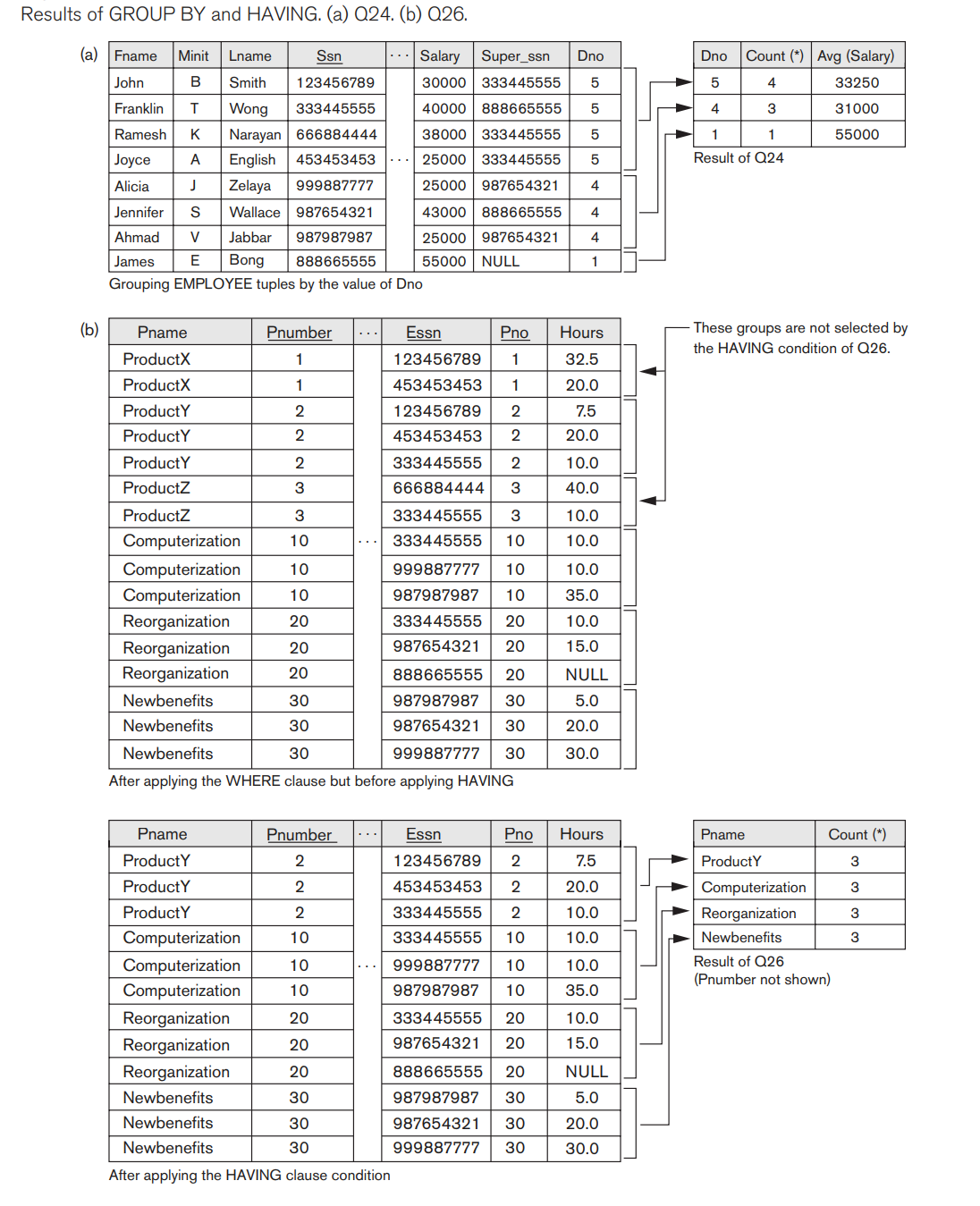
the EMPLOYEE tuples are partitioned into groups-each group having the same value for the GROUP BY attribute Dno. Hence, each group contains the employees who work in the same department. The COUNT and AVG functions are applied to each such group of tuples. Notice that the SELECT clause includes only the grouping attribute and the aggregate functions to be applied on each group of tuples.
SQL provides a HAVING clause, which can appear in conjunction with a GROUP BY clause, for this purpose. HAVING provides a condition on the summary information regarding the group of tuples associated with each value of the grouping attributes. Only the groups that satisfy the condition are retrieved in the result of the query.
For each project on which more than two employees work, retrieve the project number, the project name, and the number of employees who work on the project.

Below Page NAVIGATION Links are Provided...
All the Questions on Question Bank Is SOLVED
Follow our Instagram Page:
FutureVisionBIE
https://www.instagram.com/futurevisionbie/
Message: I'm Unable to Reply to all your Emails
so, You can DM me on the Instagram Page & any other Queries.