 MENU
MENU


NOTE!
Click on MENU to Browse between Subjects...17CS53 - DATABASE MANAGEMENT SYSTEM
Answer Script for Module 5
Solved Previous Year Question Paper
CBCS SCHEME
DATABASE MANAGEMENT SYSTEM
DBMS
[As per Choice Based Credit System (CBCS) scheme]
(Effective from the academic year 2019 -2020)
SEMESTER - V
Subject Code 17CS53
IA Marks 40
Number of Lecture Hours/Week 04
Exam Marks 60
These Questions are being framed for helping the students in the "FINAL Exams" Only
(Remember for Internals the Question Paper is set by your respective teachers).
Questions may be repeated, just to show students how VTU can frame Questions.
- ADMIN
The concurrency control is needed to overcome the following problems:
i. The Lost Update Problem:
This problem occurs when two
transactions that access the same database items have their operations
interleaved in a way that makes the value of some database items incorrect.
Suppose that transactions T1 and T2 are submitted at approximately the same
time, and suppose that their operations are interleaved as shown in Figure
1.1(a); then the final value of item X is incorrect because T2 reads the
value of X before T1 changes it in the database, and hence the updated
value resulting from T1 is lost. For example, if X = 80 at the start
(originally there were 80 reservations on the flight), N = 5 (T1 transfers
5 seat reservations from the flight corresponding to X to the flight
corresponding to Y), and M = 4 (T2 reserves 4 seats on X), the final result
should be X = 79. However, in the interleaving of operations shown in
Figure 1.1(a), it is X = 84 because the update in T1 that removed the five
seats from X was lost.
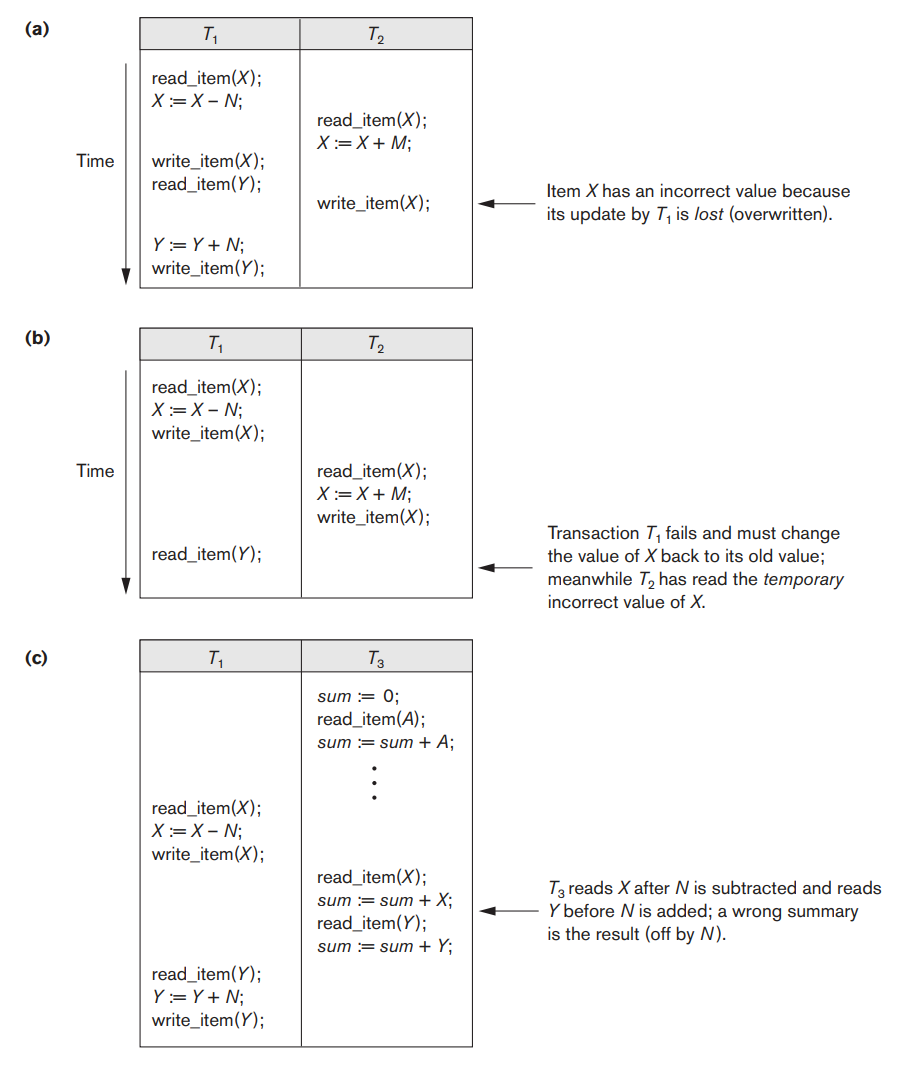
Fig 1.1: Some problems that occur when concurrent execution is uncontrolled. (a) The lost update problem. (b) The temporary update problem. (c) The incorrect summary problem
ii. The Temporary Update (or Dirty Read) Problem:
This
problem occurs when one transaction updates a database item and then the
transaction fails for some reason. Meanwhile, the updated item is accessed
(read) by another transaction before it is changed back (or rolled back) to
its original value. Figure 1.1(b) shows an example where T1 updates item X
and then fails before completion, so the system must roll back X to its
original value. Before it can do so, however, transaction T2 reads the
temporary value of X, which will not be recorded permanently in the
database because of the failure of T1. The value of item X that is read by
T2 is called dirty data because it has been created by a transaction that
has not completed and committed yet; hence, this problem is also known as
the dirty read problem.
iii. The Incorrect Summary Problem:
If one transaction is
calculating an aggregate summary function on a number of database items
while other transactions are updating some of these items, the aggregate
function may calculate some values before they are updated and others after
they are updated. For example, suppose that a transaction T3 is calculating
the total number of reservations on all the flights; meanwhile, transaction
T1 is executing. If the interleaving of operations shown in Figure 1.1(c)
occurs, the result of T3 will be off by an amount N because T3 reads the
value of X after N seats have been subtracted from it but reads the value
of Y before those N seats have been added to it.
iv. The Unrepeatable Read Problem:
Another problem that
may occur is called unrepeatable read, where a transaction T reads the same
item twice and the item is changed by another transaction T′ between
the two reads. Hence, T receives different values for its two reads of the
same item. This may occur, for example, if during an airline reservation
transaction, a customer inquires about seat availability on several
flights. When the customer decides on a particular flight, the transaction
then reads the number of seats on that flight a second time before
completing the reservation, and it may end up reading a different value for
the item.
Desirable Properties of Transactions
Transactions should possess several properties, often called the ACID properties
; they should be enforced by the
concurrency control and recovery methods of the DBMS. The following are the ACID properties
:
i. Atomicity:
A transaction is an atomic unit of
processing; it should either be performed in its entirety or not performed
at all.
ii. Consistency preservation:
A transaction should be
consistency preserving, meaning that if it is completely executed from
beginning to end without interference from other transactions, it should
take the database from one consistent state to another.
iii. Isolation:
A transaction should appear as though it
is being executed in isolation from other transactions, even though many
transactions are executing concurrently. That is, the execution of a
transaction should not be interfered with by any other transactions
executing concurrently.
iv. Durability or permanency:
The changes applied to the
database by a committed transaction must persist in the database. These
changes must not be lost because of any failure.
The atomicity property
requires that we execute a
transaction to completion. It is the responsibility of the transaction
recovery subsystem of a DBMS to ensure atomicity. If a transaction fails to
complete for some reason, such as a system crash in the midst of
transaction execution, the recovery technique must undo any effects of the
transaction on the database. On the other hand, write operations of a
committed transaction must be eventually written to disk.
The preservation of consistency
is generally
considered to be the responsibility of the programmers who write the
database programs and of the DBMS module that enforces integrity
constraints. Recall that a database state
is a collection
of all the stored data items (values) in the database at a given point in
time. A consistent state
of the database satisfies the
constraints specified in the schema as well as any other constraints on the
database that should hold. A database program should be written in a way
that guarantees that, if the database is in a consistent state before
executing the transaction, it will be in a consistent state after the
complete execution of the transaction, assuming that no interference with
other transactions occurs.
The isolation property
is enforced by the
concurrency control subsystem of the DBMS. If every transaction does not
make its updates (write operations) visible to other transactions until it
is committed, one form of isolation is enforced that solves the temporary
update problem and eliminates cascading rollbacks (see Chapter 22) but does
not eliminate all other problems.
The durability property
is the responsibility of
the recovery subsystem of the DBMS.
NOTE: This is Step wise elaboration Section 3.3 is the Answer. But
Section 3.1, 3.2 & 3.3 Will together be the two face locking
Techniques for Concurrency Control.
Some of the main techniques used to control concurrent execution of
transactions are based on the concept of locking data items. A lock
is a variable associated with a data item that
describes the status of the item with respect to possible operations that
can be applied to it. Generally, there is one lock for each data item in
the database. Locks are used as a means of synchronizing the access by
concurrent transactions to the database items.
3.1 Types of Locks and System Lock Tables
Several types of locks are used in concurrency control. To introduce locking concepts gradually, first we discuss binary locks, which are simple but are also too restrictive for database concurrency control purposes and so are not used much. Then we discuss shared/exclusive locks-also known as read/write locks-which provide more general locking capabilities and are used in database locking schemes.
3.1.1 Binary Locks:
A binary lock can have two states or values: locked and unlocked (or 1 and
0, for simplicity). A distinct lock is associated with each database item
X. If the value of the lock on X is 1, item X cannot be accessed by a
database operation that requests the item. If the value of the lock on X is
0, the item can be accessed when requested, and the lock value is changed
to 1. We refer to the current value (or state) of the lock associated with
item X as lock(X).
Two operations, lock_item and unlock_item, are used with binary locking. A transaction requests access to an item X by first issuing a lock_item(X) operation. If LOCK(X) = 1, the transaction is forced to wait. If LOCK(X) = 0, it is set to 1 (the transaction locks the item) and the transaction is allowed to access item X. When the transaction is through using the item, it issues an unlock_item(X) operation, which sets LOCK(X) back to 0 (unlocks the item) so that X may be accessed by other transactions. Hence, a binary lock enforces mutual exclusion on the data item. A description of the lock_item(X) and unlock_item(X) operations is shown in Figure 3.1.

Fig 3.1: Lock and unlock operations for binary locks.
If the simple binary locking scheme described here is used, every transaction must obey the following rules:
a. A transaction T must issue the operation lock_item(X) before any read_item(X) or write_item(X) operations are performed in T.
b. A transaction T must issue the operation unlock_item(X) after all read_item(X) and write_item(X) operations are completed in T.
c. A transaction T will not issue a lock_item(X) operation if it already holds the lock on item X.
d. A transaction T will not issue an unlock_item(X) operation unless it already holds the lock on item X.
These rules can be enforced by the lock manager module of the DBMS. Between the lock_item(X) and unlock_item(X) operations in transaction T, T is said to hold the lock on item X. At most one transaction can hold the lock on a particular item. Thus no two transactions can access the same item concurrently.
3.1.2 Shared/Exclusive (or Read/Write) Locks:
The preceding binary locking scheme is too restrictive for database items
because at most one transaction can hold a lock on a given item. We should
allow several transactions to access the same item X if they all access X
for reading purposes only. This is because read operations on the same item
by different transactions are not conflicting. However, if a transaction is
to write an item X, it must have exclusive access to X. For this purpose, a
different type of lock, called a multiple-mode lock
, is
used. In this scheme-called shared/exclusive or read/write locks
-there are three
locking operations: read_lock(X), write_lock(X), and unlock(X). A lock
associated with an item X, LOCK(X), now has three possible states:
read-locked, write-locked, or unlocked.
A read-locked
item is also called share-locked
because other
transactions are allowed to read the item, whereas awrite-locked
item
is called exclusive-locked
because a single transaction exclusively
holds the lock on the item.

Fig 3.2: Locking and unlocking operations for twomode (read/write, or shared/exclusive) locks.
When we use the shared/exclusive locking scheme, the system must enforce the following rules:
a. A transaction T must issue the operation read_lock(X) or write_lock(X) before any read_item(X) operation is performed in T.
b. A transaction T must issue the operation write_lock(X) before any write_item(X) operation is performed in T.
c. A transaction T must issue the operation unlock(X) after all read_item(X) and write_item(X) operations are completed in T.
d. A transaction T will not issue a read_lock(X) operation if it already holds a read (shared) lock or a write (exclusive) lock on item X. This rule may be relaxed for downgrading of locks, as we discuss shortly.
e. A transaction T will not issue a write_lock(X) operation if it already holds a read (shared) lock or write (exclusive) lock on item X. This rule may also be relaxed for upgrading of locks, as we discuss shortly.
f. A transaction T will not issue an unlock(X) operation unless it already holds a read (shared) lock or a write (exclusive) lock on item X.
3.1.3
Conversion (Upgrading, Downgrading) of Locks:
It is desirable to relax conditions 4 and 5 in the preceding list in order
to allow lock conversion; that is, a transaction that already holds a lock
on item X is allowed under certain conditions to convert the lock from one
locked state to another.
For example, it is possible for a transaction T to issue a read_lock(X) and
then later to upgrade
the lock by issuing a write_lock(X)
operation. If T is the only transaction holding a read lock on X at the
time it issues the write_lock(X) operation, the lock can be upgraded;
otherwise, the transaction must wait. It is also possible for a transaction
T to issue a write_lock(X) and then later to downgrade
the
lock by issuing a read_lock(X) operation.
When upgrading and downgrading of locks is used, the lock table must include transaction identifiers in the record structure for each lock (in the locking_transaction(s) field) to store the information on which transactions hold locks on the item. The descriptions of the read_lock(X) and write_lock(X) operations in Figure 3.3 must be changed appropriately to allow for lock upgrading and downgrading.
3.2
Guaranteeing Serializability by Two-Phase Locking
A transaction is said to follow the two-phase locking protocol
if all locking operations
(read_lock, write_lock) precede the first unlock operation in the
transaction. Such a transaction can be divided into two phases: an expanding or growing (first) phase
, during which new
locks on items can be acquired but none can be released; and a shrinking (second) phase
, during which existing locks
can be released but no new locks can be acquired. If lock conversion is
allowed, then upgrading of locks (from read-locked to write-locked) must be
done during the expanding phase, and downgrading of locks (from
write-locked to read-locked) must be done in the shrinking phase.
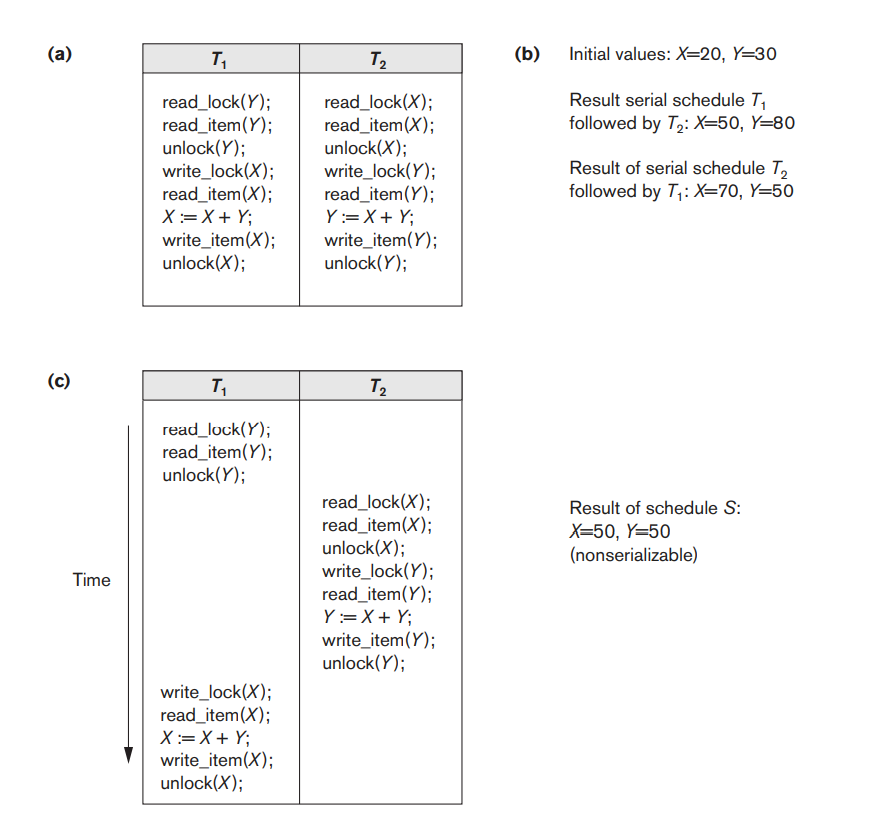
Fig 3.3: Transactions that do not obey two-phase locking. (a) Two transactions T1 and T2. (b) Results of possible serial schedules of T1 and T2. (c) A nonserializable schedule S that uses locks.
Transactions T1 and T2 in Figure 3.3(a) do not follow the two-phase locking protocol because the write_lock(X) operation follows the unlock(Y) operation in T1, and similarly the write_lock(Y) operation follows the unlock(X) operation in T2. If we enforce two-phase locking, the transactions can be rewritten as T1′ and T2′, as shown in Figure 3.4.
Now, the schedule shown in Figure 3.3(c) is not permitted for T1′ and T2′ (with their modified order of locking and unlocking operations) under the rules of locking described in Section 3.1.1 because T1′ will issue its write_lock(X) before it unlocks item Y; consequently, when T2′ issues its read_lock(X), it is forced to wait until T1′ releases the lock by issuing an unlock (X) in the schedule. However, this can lead to deadlock.
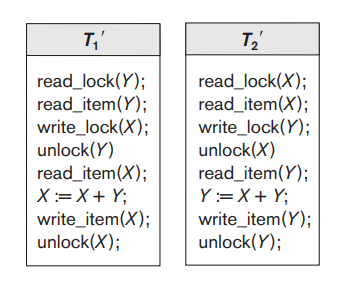
Fig 3.4: Transactions T1′ and T2′, which are the same as T1 and T2 in Figure 3.3 but follow the two-phase locking protocol. Note that they can produce a deadlock.
It can be proved that, if every transaction in a schedule follows the two-phase locking protocol, the schedule is guaranteed to be serializable, obviating the need to test for serializability of schedules. The locking protocol, by enforcing two-phase locking rules, also enforces serializability.
Although the two-phase locking protocol guarantees serializability (that is, every schedule that is permitted is serializable), it does not permit all possible serializable schedules (that is, some serializable schedules will be prohibited by the protocol).
3.2.1 Basic, Conservative, Strict, and Rigorous Two-Phase Locking:
There are a number of variations of two-phase locking (2PL). The technique
just described is known as basic 2PL
.
A variation known as conservative 2PL (or static 2PL)
requires a transaction to lock all the items it accesses before the
transaction begins execution, by predeclaring
its read-set
and write-set. Recall from Section 3.1.2 that the read-set
of a transaction is the set of all items that the transaction reads, and
the write-set
is the set of all items that it writes.
If any of the predeclared items needed cannot be locked, the transaction does not lock any item; instead, it waits until all the items are available for locking. Conservative 2PL is a deadlock-free protocol. However, it is difficult to use in practice because of the need to predeclare the read-set and writeset, which is not possible in some situations.
3.3 Dealing with Deadlock and Starvation
Deadlock occurs when each transaction T in a set of two or more transactions is waiting for some item that is locked by some other transaction T′ in the set. Hence, each transaction in the set is in a waiting queue, waiting for one of the other transactions in the set to release the lock on an item. But because the other transaction is also waiting, it will never release the lock.
A simple example is shown in Figure 3.5(a), where the two transactions T1′ and T2′ are deadlocked in a partial schedule; T1′ is in the waiting queue for X, which is locked by T2′, whereas T2′ is in the waiting queue for Y, which is locked by T1′. Meanwhile, neither T1′ nor T2′ nor any other transaction can access items X and Y.
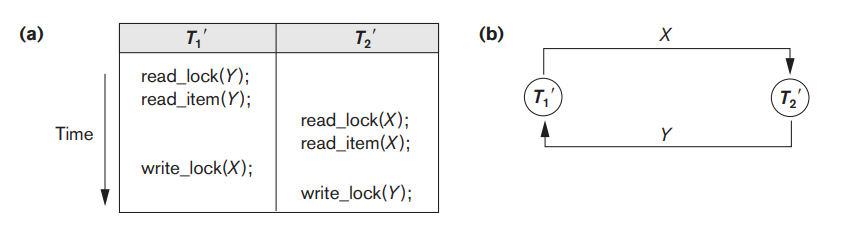
Fig 3.5: Illustrating the deadlock problem. (a) A partial schedule of T1′ and T2′ that is in a state of deadlock. (b) A wait-for graph for the partial schedule in (a).
3.3.1 Deadlock Prevention Protocols
:
One way to prevent deadlock is to use a deadlock prevention protocol
. One deadlock prevention
protocol, which is used in conservative two-phase locking, requires that
every transaction lock all the items it needs in advance (which is
generally not a practical assumption)-if any of the items cannot be
obtained, none of the items are locked.
Rather, the transaction waits and then tries again to lock all the items it needs. Obviously, this solution further limits concurrency. A second protocol, which also limits concurrency, involves ordering all the items in the database and making sure that a transaction that needs several items will lock them according to that order. This requires that the programmer (or the system) is aware of the chosen order of the items, which is also not practical in the database context.
A number of other deadlock prevention schemes have been proposed that make
a decision about what to do with a transaction involved in a possible
deadlock situation: Should it be blocked and made to wait or should it be
aborted, or should the transaction preempt and abort another transaction?
Some of these techniques use the concept of transaction timestamp TS(T′),
which is a unique
identifier assigned to each transaction.
The timestamps are typically based on the order in which transactions are started; hence, if transaction T1 starts before transaction T2, then TS(T1) < TS(T2). Notice that the older transaction (which starts first) has the smaller timestamp value. Two schemes that prevent deadlock are called wait-die and wound-wait. Suppose that transaction Ti tries to lock an item X but is not able to because X is locked by some other transaction Tj with a conflicting lock.
The rules followed by these schemes are:
a) Wait-die:
If TS(Ti) < TS(Tj), then (Ti older than
Tj) Ti is allowed to wait; otherwise (Ti younger than Tj ) abort Ti (Ti
dies) and restart it later with the same timestamp.
b) Wound-wait:
If TS(Ti) < TS(Tj ), then (Ti older than
Tj ) abort Tj (Ti wounds Tj ) and restart it later with the same timestamp;
otherwise (Ti younger than Tj ) Ti is allowed to wait.
Another group of protocols that prevent deadlock do not require timestamps.
These include the no waiting (NW)
and cautious waiting (CW) algorithms
. In the no waiting
algorithm, if a transaction is unable to obtain a lock, it is immediately
aborted and then restarted after a certain time delay without checking
whether a deadlock will actually occur or not. In this case, no transaction
ever waits, so no deadlock will occur. However, this scheme can cause
transactions to abort and restart needlessly.
The cautious waiting algorithm was proposed to try to reduce the number of needless aborts/restarts. Suppose that transaction Ti tries to lock an item X but is not able to do so because X is locked by some other transaction Tj with a conflicting lock. The cautious waiting rule is as follows:
a) Cautious waiting:
If Tj is not blocked (not waiting for
some other locked item), then Ti is blocked and allowed to wait; otherwise
abort Ti.
3.3.2 Deadlock Detection:
An alternative approach to dealing with deadlock is deadlock detection, where the system checks if a state of deadlock actually exists. This solution is attractive if we know there will be little interference among the transactions-that is, if different transactions will rarely access the same items at the same time.
This can happen if the transactions are short and each transaction locks only a few items, or if the transaction load is light. On the other hand, if transactions are long and each transaction uses many items, or if the transaction load is heavy, it may be advantageous to use a deadlock prevention scheme.
A simple way to detect a state of deadlock is for the system to construct
and maintain a wait-for graph
. One node is created in the
wait-for graph for each transaction that is currently executing. Whenever a
transaction Ti is waiting to lock an item X that is currently locked by a
transaction Tj , a directed edge (Ti → Tj ) is created in the
wait-for graph. When Tj releases the lock(s) on the items that Ti was
waiting for, the directed edge is dropped from the wait-for graph. We have
a state of deadlock if and only if the wait-for graph has a cycle. One
problem with this approach is the matter of determining when the system
should check for a deadlock. One possibility is to check for a cycle every
time an edge is added to the waitfor graph, but this may cause excessive
overhead.
If the system is in a state of deadlock, some of the transactions causing
the deadlock must be aborted. Choosing which transactions to abort is known
as victim selection
. The algorithm for victim selection
should generally avoid selecting transactions that have been running for a
long time and that have performed many updates, and it should try instead
to select transactions that have not made many changes (younger
transactions).
Timeouts:
Another simple scheme to deal with deadlock is the use of timeouts. This
method is practical because of its low overhead and simplicity. In this
method, if a transaction waits for a period longer than a system-defined
timeout period, the system assumes that the transaction may be deadlocked
and aborts it-regardless of whether a deadlock actually exists.
Starvation:
Another problem that may occur when we use locking is starvation
, which occurs when a transaction cannot proceed
for an indefinite period of time while other transactions in the system
continue normally. This may occur if the waiting scheme for locked items is
unfair in that it gives priority to some transactions over others. One
solution for starvation is to have a fair waiting scheme, such as using a first-come-first-served
queue; transactions are enabled to
lock an item in the order in which they originally requested the lock.
This recovery scheme does not require the use of a log in a single-user environment. In a multiuser environment, a log may be needed for the concurrency control method. Shadow paging considers the database to be made up of a number of fixedsize disk pages (or disk blocks)-say, n-for recovery purposes.
A directory
with n entries is constructed, where the ith
entry points to the ith database page on disk. The directory is kept in
main memory if it is not too large, and all references-reads or writes-to
database pages on disk go through it. When a transaction begins executing,
the current directory
-whose entries point to the most
recent or current database pages on disk-is copied into a shadow directory
. The shadow directory is then saved on
disk while the current directory is used by the transaction.
During transaction execution, the shadow directory is never modified. When a write_item operation is performed, a new copy of the modified database page is created, but the old copy of that page is not overwritten.
Instead, the new page is written elsewhere-on some previously unused disk block. The current directory entry is modified to point to the new disk block, whereas the shadow directory is not modified and continues to point to the old unmodified disk block.
Figure 4.1 illustrates the concepts of shadow and current directories. For pages updated by the transaction, two versions are kept. The old version is referenced by the shadow directory and the new version by the current directory
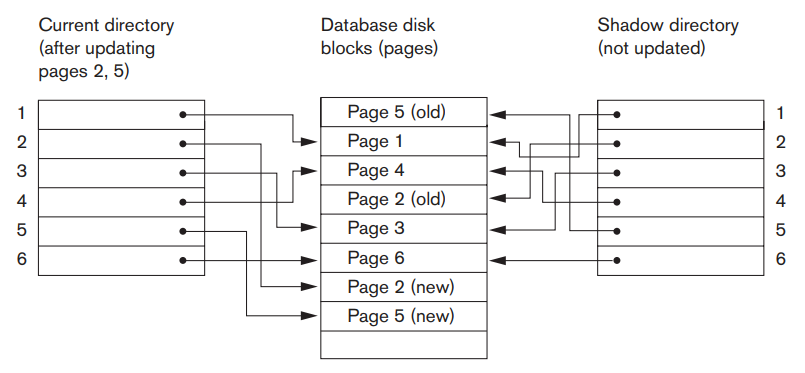
Fig 4.1: An example of shadow paging.
To recover from a failure during transaction execution, it is sufficient to free the modified database pages and to discard the current directory. The state of the database before transaction execution is available through the shadow directory, and that state is recovered by reinstating the shadow directory. The database thus is returned to its state prior to the transaction that was executing when the crash occurred, and any modified pages are discarded. Committing a transaction corresponds to discarding the previous shadow directory. Since recovery involves neither undoing nor redoing data items, this technique can be categorized as a NO-UNDO/NO-REDO technique for recovery.
In a multiuser environment with concurrent transactions, logs and checkpoints must be incorporated into the shadow paging technique. One disadvantage of shadow paging is that the updated database pages change location on disk. This makes it difficult to keep related database pages close together on disk without complex storage management strategies. Furthermore, if the directory is large, the overhead of writing shadow directories to disk as transactions commit is significant.
A further complication is how to handle garbage collection
when a transaction commits. The old pages referenced by the shadow
directory that have been updated must be released and added to a list of
free pages for future use. These pages are no longer needed after the
transaction commits. Another issue is that the operation to migrate between
current and shadow directories must be implemented as an atomic operation.
Refer 2nd Question & Answer.
Below Page NAVIGATION Links are Provided...
All the Questions on Question Bank Is SOLVED
Follow our Instagram Page:
FutureVisionBIE
https://www.instagram.com/futurevisionbie/
Message: I'm Unable to Reply to all your Emails
so, You can DM me on the Instagram Page & any other Queries.