 MENU
MENU


NOTE!
Click on MENU to Browse between Subjects...18CS43/17CS64 - OPERATING SYSTEMS
4TH & 6TH SEMESTER ISE & CSE
Answer Script for Module 1
Solved Previous Year Question Paper
CBCS SCHEME
OPERATING SYSTEMS
[As per Choice Based Credit System (CBCS) scheme]
(Effective from the academic year 2017 - 2018)
SEMESTER - IV/VI
Subject Code 18CS43/17CS64
IA Marks 40
Number of Lecture Hours/Week 3
Exam Marks 60
These Questions are being framed for helping the students in the "FINAL Exams" Only
(Remember for Internals the Question Paper is set by your respective teachers).
Questions may be repeated, just to show students how VTU can frame Questions.
- ADMIN
18CS43/17CS64 - OPERATING SYSTEMS
4TH & 6TH SEMESTER ISE & CSE
Answer Script for Module 1
1.1 Operating System:
An operating system
is a program that manages the computer hardware. It also provides a basis
for application programs and acts as an intermediary between the computer
user and the computer hardware.
An operating system
provides the environment within which
programs are executed. Internally, operating systems vary greatly in their
makeup, since they are organized along many different lines.
One of the most important aspects of operating systems is the ability to multi-program. A single user cannot, in general, keep either the CPU or the I/O devices busy at all times.
1.2 Multi-Programming System:
Multiprogramming
increases CPU utilization by organizing jobs (code and data) so that the
CPU always has one to execute.
The idea is as follows: The operating system keeps several jobs in memory simultaneously (Figure 1.1). This set of jobs can be a subset of the jobs kept in the job pool-which contains all jobs that enter the system-since the number of jobs that can be kept simultaneously in memory is usually smaller than the number of jobs that can be kept in the job pool. The operating system picks and begins to execute one of the jobs in memory. Eventually, the job may have to wait for some task, such as an I/O operation, to complete.
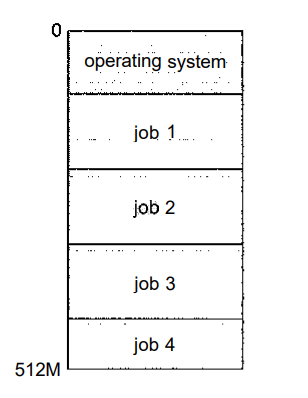
Fig 1.1: Memory layout for a multiprogramming system.
In a non-multiprogrammed
system, the CPU would sit idle.
In a multiprogrammed system
, the operating system simply
switches to, and executes, another job. When that job needs to wait, the
CPU is switched to another job, and so on. Eventually, the first job
finishes waiting and gets the CPU back. As long as at least one job needs
to execute, the CPU is never idle.
Multiprogrammed systems
provide an environment in which the various system resources (for example,
CPU, memory, and peripheral devices) are utilized effectively, but they do
not provide for user interaction with the computer system.
1.3 Time Shared System:
Time sharing
(or multitasking) is a logical extension of multiprogramming. In
time-sharing systems, the CPU executes multiple jobs by switching among
them, but the switches occur so frequently that the users can interact with
each program while it is running.
Time sharing
requires an interactive
(or hands-on) computer system,
which provides direct communication
between the user
and the system
.
The user
gives instructions to the operating system or to
a program directly, using a input device such as a keyboard or a mouse, and
waits for immediate results on an output device. Accordingly, the response
time should be short-typically less than one second
.
A time-shared operating
system
allows
many users to share the computer simultaneously. Since each action or
command in a time-shared system tends to be short, only a little CPU time
is needed for each user.
As the system switches rapidly
from one user to the next,
each user is given the impression that the entire computer system is
dedicated to his use, even though it is being shared among many users.
A time-shared operating system
uses CPU scheduling
and multiprogramming
to
provide each user with a small portion of a time-shared computer. Each user
has at least one separate program in memory.
In a time-sharing system, the operating system
must ensure reasonable response time
, which is sometimes accomplished
through swapping, where processes are swapped in and out of main memory to the disk
. A more
common method for achieving this goal is virtual memory
, a
technique that allows the execution of a process that is not completely in
memory.
Time-sharing systems must also provide a file system
. The
file system resides on a collection of disks
; hence, disk management
must be provided. Also, time-sharing
systems provide a mechanism for protecting resources from inappropriate use
. To ensure
orderly execution, the system must provide mechanisms for job synchronization and communication
, and it may
ensure that jobs do not get stuck in a deadlock, forever waiting for
one another.
2.1 Dual Mode Operation:
In order to ensure the proper execution of the operating system, we must be able to distinguish between the execution of operating-system code and user defined code. The approach taken by most computer systems is to provide hardware support that allows us to differentiate among various modes of execution.
At the very least, we need two separate modes of operation: user mode
and kernel mode
(also called
supervisor mode, system mode, or privileged mode)
A bit, called the mode bit
, is added to thehardware of the computer
to indicate the current mode: kernel (0) or user (1).
With the mode bit, we are able to
distinguish between a task that is executed on behalf of the operating
system and one that is executed on behalf of the user.
When the computer system is executing on behalf of a user application, the system is in user mode. However, when a user application requests a service from the operating system (via a system call), it must transition from user to kernel mode to fulfill the request. This is shown in Figure 2.1.
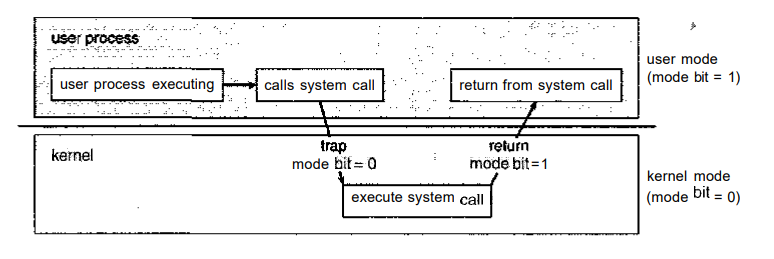
Fig 2.1: Transition from user to kernel mode.
At system boot time, the hardware starts in kernel mode
.
The operating system is then loaded and starts user applications in user
mode. Whenever a trap or interrupt occurs
, the hardware
switches from user mode to kernel mode
(that is, changes
the state of the mode bit to 0). Thus, whenever the
operating system gains control of the computer, it is in kernel mode
. The system always switches to user mode (by setting the mode bit to 1)
before passing control to a user program.
The dual mode of operation
provides us with the means forprotecting the operating system
from errant users-and errant users
from one another. We
accomplish this protection by designating some of the machine instructions
that may cause harm as privileged instructions
.
The hardware allows privileged instructions to be executed only in kernel mode. If an attempt is made to execute a privileged instruction in user mode, the hardware does not execute the instruction but rather treats it as illegal and traps it to the operating system.
The instruction to switch to user mode is an example of a privileged instruction. Some other examples include I/O control, timer management, and interrupt management.
The lack of a hardware-supported dual mode can cause serious shortcomings in an operating system. For instance, MS-DOS was written for the Intel 8088 architecture, which has no mode bit and therefore no dual mode. A user program running awry can wipe out the operating system by writing over it with data; and multiple programs are able to write to a device at the same time, with possibly disastrous results.
3.1 System calls:
System calls provide an interface to the services made available by an operating system. These calls are generally available as routines written in C and C++, although certain low-level tasks (for example, tasks where hardware must be accessed directly), may need to be written using assembly-language instructions.
3.2 Types of System calls:
System calls can be grouped roughly into five major categories:
i. process control,
ii. file manipulation,
iii. device manipulation,
iv. information maintenance, and
v. communications.
3.2.1 Process Control:
A running program needs to be able to halt its execution either normally (end) or abnormally (abort). If a system call is made to terminate the currently running program abnormally, or if the program runs into a problem and causes an error trap, a dump of memory is sometimes taken and an error message generated. The dump is written to disk and may be examined by a debugger a system program designed to aid the programmer in finding and correcting bugs to determine the cause of the problem.

Fig 3.1: Types of system calls.
3.2.2 File Management
We first need to be able to create and delete files. Either system call requires the name of the file and perhaps some of the file's attributes. Once the file is created, we need to open it and to use it. We may also read, write, or reposition (rewinding or skipping to the end of the file, for example). Finally, we need to close the file, indicating that we are no longer using it.
We may need these same sets of operations for directories if we have a directory structure for organizing files in the file system. In addition, for either files or directories, we need to be able to determine the values of various attributes and perhaps to reset them if necessary.
File attributes include the file name, a file type, protection codes, accounting information, and so on. At least two system calls, get file attribute and set fil e attribute, are required for this function. Some operating systems provide many more calls, such as calls for file move and copy
3.2.3 Device Management
A process may need several resources to execute-main memory, disk drives, access to files, and so on. If the resources are available, they can be granted, and control can be returned to the user process. Otherwise, the process will have to wait until sufficient resources are available.
The various resources controlled by the operating system can be thought of as devices. Some of these devices are physical devices (for example, tapes), while others can be thought of as abstract or virtual devices (for example, files). If there are multiple users of the system, the system may require us to first request the device, to ensure exclusive use of it.
After we are finished with the device, we release it. These functions are similar to the open and close system calls for files. Other operating systems allow unmanaged access to devices. The hazard then is the potential for device contention and perhaps deadlock.
Once the device has been requested (and allocated to us), we can read, write, and (possibly) reposition the device, just as we can with files. In fact, the similarity between I/O devices and files is so great that many operating systems, including UNIX, merge the two into a combined file-device structure. In this case, a set of system calls is used on files and devices. Sometimes, I/O devices are identified by special file names, directory placement, or file attributes
3.2.4 Information Maintenance
Many system calls exist simply for the purpose of transferring information between the user program and the operating system. For example, most systems have a system call to return the current time and date. Other system calls may return information about the system, such as the number of current users, the version number of the operating system, the amount of free memory or disk space, and so on.
In addition, the operating system keeps information about all its processes, and system calls are used to access this information. Generally, calls are also used to reset the process information (get process attribute s and s e t process attributes).
3.2.5 Communication
There are two common models of inter process communication: the message passing model and the shared-memory model. In the message-passing model, the communicating processes exchange messages with one another to transfer information. Messages can be exchanged between the processes either directly or indirectly through a common mailbox.
Before communication can take place, a connection must be opened. The name of the other communicator must be known, be it another process on the same system or a process on another computer connected by a communications network. Each computer in a network has a host name by which it is commonly known.
A host also has a network identifier, such as an IP address. Similarly, each process has a process name, and this name is translated into an identifier by which the operating system can refer to the process. The get host id and get process id system calls do this translation. The identifiers are then passed to the general purpose open and close calls provided by the file system or to specific open connection and close connection system calls, depending on the system's model of communication.
The recipient process usually must give its permission for communication to take place with an accept connection call. Most processes that will be receiving connections are special-purpose daemons, which are systems programs provided for that purpose.
They execute a wait for connect ion call and are awakened when a connection is made. The source of the communication, known as the client, and the receiving daemon, known as a server, then exchange messages by using read message and write message system calls. The close connection call terminates the communication.
4.1 Process State:
As a process executes, it changes state. The state of a process is defined in part by the current activity of that process. Each process may be in one of the following states:
i. New
: The process is being created.
ii. Running
: Instructions are being executed.
iii. Waiting
: The process is waiting for some event to
occur (such as an I/O completion or reception of a signal).
iv. Ready:
The process is waiting to be assigned to a
processor.
v. Terminated:
The process has finished execution.
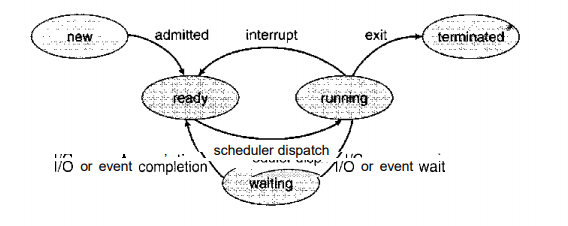
Fig 4.1: State Diagram of Process.
These names are arbitrary, and they vary across operating systems. The states that they represent are found on all systems, however. Certain operating systems also more finely delineate process states. It is important to realize that only one process can be running on any processor at any instant. Many processes may be ready and limiting, however. The state diagram corresponding to these states is presented in Figure 4.1.
4.2 Process Control Block
Each process is represented in the operating system by aprocess control block (PCB)
-also called a task control block
. A PCB is shown in Figure 4.2. It
contains many pieces of information associated with a specific process,
including these:
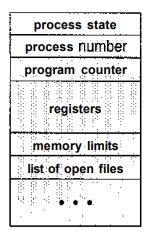
Fig 4.2 : Process control block (PCB)
i. Process state:
The state may be new, ready, running,
waiting, halted, and so on.
ii. Program counter:
The counter indicates the address of
the next instruction to be executed for this process.
iii. CPU registers:
The registers vary in number and type,
depending on the computer architecture. They include accumulators, index
registers, stack pointers, and general-purpose registers, plus any
condition-code information. Along with the program counter, this state
information must be saved when an interrupt occurs, to allow the process to
be continued correctly afterward.
iv. CPU-scheduling information:
This information includes
a process priority, pointers to scheduling queues, and any other scheduling
parameters.
v. Memory-management information:
This information may
include such information as the value of the base and limit registers, the
page tables, or the segment tables, depending on the memory system used by
the operating system.
vi. Accounting information:
This information includes the
amount of CPU and real time used, time limits, account numbers, job or
process numbers, and so on.
vii. I/O status information:
This information includes the
list of I/O devices allocated to the process, a list of open files, and so
on.
5.1 Inter Process Communication (IPC):
Processes executing concurrently in the operating system may be either
independent processes or cooperating processes. A process is independent
if it cannot affect or be affected by the
other processes executing in the system. Any process that does not share
data with any other process is independent.
A process is cooperating
if it can affect or be affected
by the other processes executing in the system. Clearly, any process that
shares data with other processes is a cooperating process.
There are several reasons for providing an environment that allows process cooperation:
i. Information sharing
: Since several users may be
interested in the same piece of information (for instance, a shared file),
we must provide an environment to allow concurrent access to such
information.
ii. Computation speedup:
If we want a particular task to
run faster, we must break it into subtasks, each of which will be executing
in parallel with the others. Notice that such a speedup can be achieved
only if the computer has multiple processing elements (such as CPUs or I/O
channels).
iii. Modularity:
We may want to construct the system in a
modular fashion, dividing the system functions into separate processes or
threads.
iv. Convenience:
Even an individual user may work on many
tasks at the same time. For instance, a user may be editing, printing, and
compiling in parallel.
5.2 Types of IPC's:
Cooperating processes
require an inter process communication (IPC)
mechanism
that will allow them to exchange data and information. There are two
fundamental models of inter process communication:
(1) shared memory
and
(2) message passing
.
In the shared-memory model
, a region of memory that is
shared by cooperating processes is established. Processes can then exchange
information by reading and writing data to the shared region.
In the message passing model,
communication takes place by
means of messages exchanged between the cooperating processes.
Fig 5.1: Communications models, (a) Message passing, (b) Shared memory.
5.2.1 Shared-Memory Systems
Inter process communication using shared memory requires communicating processes to establish a region of shared memory. Typically, a shared-memory region resides in the address space of the process creating the shared-memory segment. Other processes that wish to communicate using this shared-memory segment must attach it to their address space. Recall that, normally, the operating system tries to prevent one process from accessing another process's memory.
Shared memory requires that two or more processes agree to remove this restriction. They can then exchange information by reading and writing data in the shared areas.
The form of the data and the location are determined by these processes and are not under the operating system's control. The processes are also responsible for ensuring that they are not writing to the same location simultaneously.
To illustrate the concept of cooperating processes, let's consider the producer-consumer problem, which is a common paradigm for cooperating processes. A producer process produces information that is consumed by a consumer process.
For example, a compiler may produce assembly code, which is consumed by an assembler. The assembler, in turn, may produce object modules, which are consumed by the loader. The producer-consumer problem also provides a useful metaphor for the client-server paradigm.
One solution to the producer-consumer problem uses shared memory. To allow producer and consumer processes to run concurrently, we must have available a buffer of items that can be filled by the producer and emptied by the consumer. This buffer will reside in a region of memory that is shared by the producer and consumer processes.
A producer can produce one item while the consumer is consuming another item. The producer and consumer must be synchronized, so that the consumer does not try to consume an item that has not yet been produced.
Two types of buffers
can be used: The unbounded buffer
places no practical
limit on the size of the buffer. The consumer may have to wait for new
items, but the producer can always produce new items. The bounded buffer
assumes a fixed buffer size. In this case,
the consumer must wait if the buffer is empty, and the producer must wait
if the buffer is full.
5.2.2 Message-Passing Systems:
Message passing provides a mechanism to allow processes to communicate and to synchronize their actions without sharing the same address space and is particularly useful in a distributed environment, where the communicating processes may reside on different computers connected by a network.
For example, a chat program used on the World Wide Web could be designed so that chat participants communicate with one another by exchanging messages.
A message-passing facility provides at least two operations: send(message) and receive(message).
Messages sent by a
process can be of either fixed or variable size. If only fixed-sized
messages can be sent, the system-level implementation is straightforward.
This restriction, however, makes the task of programming more difficult. Conversely, variable-sized messages require a more complex system-level implementation, but the programming task becomes simpler. This is a common kind of trade off seen throughout operating system design
If processes P and Q want to communicate, they must send messages to and receive messages from each other; a communication link must exist between them. This link can be implemented in a variety of ways. We are concerned here not with the link's physical implementation but rather with its logical implementation. Here are several methods for logically implementing a link and the send()/receive () operations:
i. Direct or indirect communication
ii. Synchronous or asynchronous communication
iii. Automatic or explicit buffering
Below Page NAVIGATION Links are Provided...
All the Questions on Question Bank Is SOLVED