 MENU
MENU


×
NOTE!
Click on MENU to Browse between Subjects...
Advertisement
18CS43/17CS64 - OPERATING SYSTEMS
4TH & 6TH SEMESTER ISE & CSE
Answer Script for Module 2
Solved Previous Year Question Paper
CBCS SCHEME
OPERATING SYSTEMS
[As per Choice Based Credit System (CBCS) scheme]
(Effective from the academic year 2017 - 2018)
SEMESTER - IV/VI
Subject Code 18CS43/17CS64
IA Marks 40
Number of Lecture Hours/Week 3
Exam Marks 60
Advertisement
These Questions are being framed for helping the students in the "FINAL Exams" Only
(Remember for Internals the Question Paper is set by your respective teachers).
Questions may be repeated, just to show students how VTU can frame Questions.
- ADMIN
18CS43/17CS64 - OPERATING SYSTEMS
4TH & 6TH SEMESTER ISE & CSE
Answer Script for Module 2
×
CLICK ON THE QUESTIONS TO VIEW ANSWER
Answer:
1.1 Premptive priority scheduling algorithm:

1.2 non-premptive priority scheduling algorithm:

Advertisement
Answer:
2.1 CPU Scheduling:
CPU scheduling
is the basis of multi-programmed operating systems. By switching the CPU
among processes, the operating system can make the computer more
productive. So therefore CPU Scheduling is necessary.
2.2 Scheduling Criteria's:
Different CPU scheduling algorithms have different properties, and the choice of a particular algorithm may favour one class of processes over another. In choosing which algorithm to use in a particular situation, we must consider the properties of the various algorithms.
Many criteria have been suggested for comparing CPU scheduling algorithms. Which characteristics are used for comparison can make a substantial difference in which algorithm is judged to be best. The criteria include the following:
i. CPU utilization:
We want to keep the CPU as busy as possible. Conceptually, CPU utilization
can range from 0 to 100 percent. In a real system, it should range from 40
percent (for a lightly loaded system) to 90 percent (for a heavily used
system).
ii. Throughput:
If the CPU is busy executing processes, then work is being done. One
measure of work is the number of processes that are completed per time
unit, called throughput. For long processes, this rate may be one process
per hour; for short transactions, it may be 10 processes per second.
iii. Turnaround time:
From the point of view of a particular process, the important criterion is
how long it takes to execute that process. The interval from the time of
submission of a process to the time of completion is the turnaround time.
Turnaround time is the sum of the periods spent waiting to get into memory,
waiting in the ready queue, executing on the CPU, and doing I/O.
iv. Waiting time:
The CPU scheduling algorithm does not affect the amount of time during
which a process executes or does I/O; it affects only the amount of time
that a process spends waiting in the ready queue. Waiting time is the sum
of the periods spent waiting in the ready queue.
v. Response time:
In an interactive system, turnaround time may not be the best criterion.
Often, a process can produce some output fairly early and can continue
computing new results while previous results are being output to the user.
Thus, another measure is the time from the submission of a request until
the first response is produced. This measure, called response time, is the
time it takes to start responding, not the time it takes to output the
response. The turnaround time is generally limited by the speed of the
output device.
It is desirable to maximize CPU utilization and throughput and to minimize turnaround time, waiting time, and response time. In most cases, we optimize the average measure. However, under some circumstances, it is desirable to optimize the minimum or maximum values rather than the average. For example, to guarantee that all users get good service, we may want to minimize the maximum response time.
Answer:
3.1 Multithreading Models:
i. There are two types of threads to be managed in a modern system: User threads and kernel threads.
ii. User threads are the threads that application programmers would put into their programs. They are supported above the kernel, without kernel support.
iii. Kernel threads are supported within the kernel of the OS itself. All modern OS support kernel level threads, allowing the kernel to perform multiple tasks simultaneously.
iv. In a specific implementation, the user threads must be mapped to kernel threads, using one of the following models.
There are three Models in Multithreading & Are as follows:
i. Many-to-one Model
ii. One-to-One Model
iii. Many-to-Many Model
3.1.1 Many-To-One Model
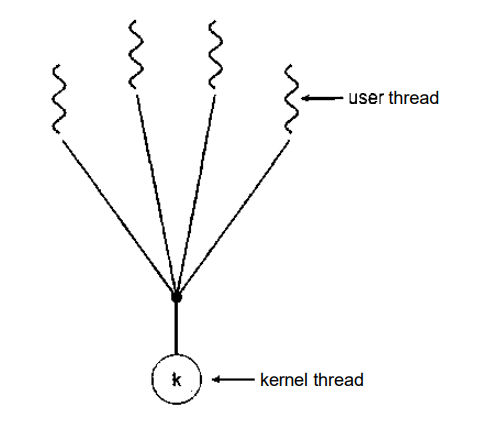
Fig 3.1 Many-to-One Model
i. In the many-to-one model, many user-level threads are all mapped onto a single kernel thread.
ii. Thread management is handled by the thread library in user space, which is very efficient.
iii. If a blocking system call is made by one of the threads, then the entire process blocks. Thus blocking the other user threads from continuing the execution.
iv. Only one user thread can access the kernel at a time, as there is only one kernel thread. Thus the threads are unable to run in parallel on multiprocessors.
v. Green threads of Solaris and GNU Portable Threads implement the many-to-one model.
3.1.2 One-to-One Model:
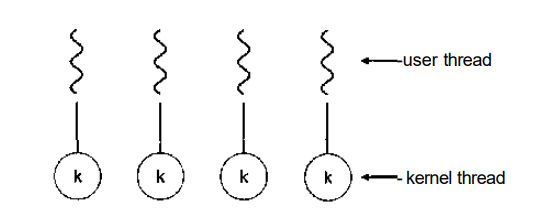
Fig 3.2 One-to-One Model
i. The one-to-one model creates a separate kernel thread to handle each user thread.
ii. One-to-one model overcomes the problems listed above involving blocking system calls and the splitting of processes across multiple CPUs.
iii. However, the overhead of managing the one-to-one model is more significant, involving more overhead and slowing down the system.
iv. This model places a limit on the number of threads created.
v. Linux and Windows from 95 to XP implement the one-to-one model for threads.
3.1.3 Many-to-Many Model:
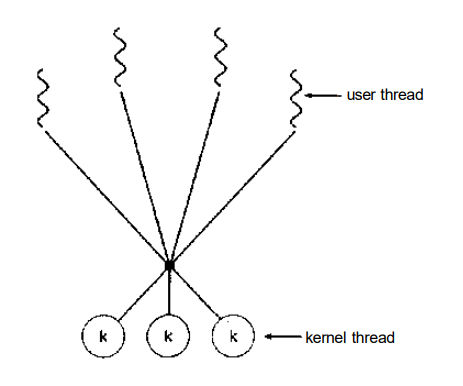
Fig 3.3 Many-to-Many Model
i. The many-to-many model multiplexes any number of user threads onto an equal or smaller number of kernel threads, combining the best features of the one-to-one and many-to-one models.
ii. Users have no restrictions on the number of threads created.
iii. Blocking kernel system calls do not block the entire process.
iv. Processes can be split across multiple processors.
v. Individual processes may be allocated variable numbers of kernel threads, depending on the number of CPUs present and other factors.
vi. This model is also called as two-tier model.
vii. It is supported by operating system such as IRIX, HP-UX, and Tru64 UNIX.
Advertisement
Answer:
4.1 Semaphores:
The various hardware-based solutions to the critical-section problem (using the TestAndSet( ) and Swap( ) instructions) are complicated for application programmers to use. To overcome this difficulty, we can use a synchronization tool called a semaphore.
A semaphore S is an integer variable that, apart from initialization, is accessed only through two standard atomic operations: wait( ) and signal( ). The wait( ) operation was originally termed P (from the Dutch probercn, "to test"); signal( ) was originally called V (from verhogen, "to increment"). The definition of wait 0 is as follows:
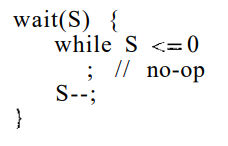
4.2 Semaphore Usage:
Operating systems often distinguish between counting and binary semaphores.
The value of a counting semaphore can range over an unrestricted domain. The value of a binary semaphore can range only between 0 and 1.
On some systems, binary semaphores are known as mutex locks, as they are locks that provide mutual exclusion.
We can use binary semaphores to deal with the critical-section problem for multiple processes. The n processes share a semaphore, mutex, initialized to 1. Each process P, is organized as shown in Figure 4.2.
Counting semaphores can be used to control access to a given resource consisting of a finite number of instances. The semaphore is initialized to the number of resources available.
Each process that wishes to use a resource performs a wait( ) operation on the semaphore (thereby decrementing the count). When a process releases a resource, it performs a signal () operation (incrementing the count). When the count for the semaphore goes to 0, all resources are being used. After that, processes that wish to use a resource will block until the count becomes greater than 0.
We can also use semaphores to solve various synchronization problems. For example, consider two concurrently running processes: P1 with a statement S1 and P2 with a statement S2. Suppose we require that S2 be executed only after S1 has completed. We can implement this scheme readily by letting P 1 and P2 share a common semaphore synch, initialized to 0, and by inserting the statements
S1;
signal(synch);
in process P1, and the statements
wait(synch);
S2;
in process P2. Because synch is initialized to 0, P2 will execute S2 only after P1 has invoked signal (synch), which is after statement S1 has been executed.

Fig 4.2 Mutual-exclusion implementation with semaphores.
4.3 Semaphore Implementation:
The main disadvantage of the semaphore definition given here is that it requires busy waiting. While a process is in its critical section, any other process that tries to enter its critical section must loop continuously in the entry code. This continual looping is clearly a problem in a real multiprogramming system, where a single CPU is shared among many processes.
Busy waiting wastes CPU cycles that some other process might be able to use productively. This type of semaphore is also called a spinlock because the process "spins" while waiting for the lock. (Spinlocks do have an advantage in that no context switch is required when a process must wait on a lock, and a context switch may take considerable time.
Thus, when locks are expected to be held for short times, spinlocks are useful; they are often employed on multiprocessor systems where one thread can "spin" on one processor while another thread performs its critical section on another processor.)
To overcome the need for busy waiting, we can modify the definition of the wait( ) and signal( ) semaphore operations. When a process executes the wait( ) operation and finds that the semaphore value is not positive, it must wait. However, rather than engaging in busy waiting, the process can block itself.
The block operation places a process into a waiting queue associated with the semaphore, and the state of the process is switched to the waiting state. Then control is transferred to the CPU scheduler, which selects another process to execute.
A process that is blocked, waiting on a semaphore S, should be restarted when some other process executes a signal( ) operation. The process is restarted by a wakeup( ) operation, which changes the process from the waiting state to the ready state.
The process is then placed in the ready queue. (The CPU may or may not be switched from the running process to the newly ready process, depending on the CPU-scheduling algorithm.)
To implement semaphores under this definition, we define a semaphore as a "C" struct:

Each semaphore has an integer value and a list of processes list. When a process must wait on a semaphore, it is added to the list of processes. A signal( ) operation removes one process from the list of waiting processes and awakens that process.
The wait () semaphore operation can now be defined as

The signal 0 semaphore operation can now be defined as

The block( ) operation suspends the process that invokes it. The wakeup(P) operation resumes the execution of a blocked process P. These two operations are provided by the operating system as basic system calls.
Answer:
5.1 Classical Problems of Synchronization are as follows:
i. Bounded-Buffer Problem
ii. Readers and Writers Problem
iii. Dining-Philosophers Problem
5.2 Reader-Write problem with Semaphore:
A database is to be shared among several concurrent processes. Some of these processes may want only to read the database, whereas others may want to update (that is, to read and write) the database.
We distinguish between these two types of processes by referring to the
former as readers and to the latter as writers
. Obviously,
if two readers access the shared data simultaneously, no adverse affects
will result. However, if a writer and some other thread (either a reader or
a writer) access the database simultaneously, chaos may ensue.
To ensure that these difficulties do not arise, we require that the writers
have exclusive access to the shared database. This synchronization problem
is referred to as the readers-writers problem
. Since it
was originally stated, it has been used to test nearly every new
synchronization primitive.
The readers-writers problem has several variations, all involving priorities. The simplest one, referred to as the first readers-writers problem, requires that no reader will be kept waiting unless a writer has already obtained permission to use the shared object. In other words, no reader should wait for other readers to finish simply because a writer is waiting.
The second readers-writers problem requires that, once a writer is ready, that writer performs its write as soon as possible. In other words, if a writer is waiting to access the object, no new readers may start reading.
A solution to either problem may result in starvation. In the first case, writers may starve; in the second case, readers may starve. For this reason, other variants of the problem have been proposed.
we present a solution to the first readers-writers problem. Refer to the bibliographical notes at the end of the chapter for references describing starvation-free solutions to the second readers-writers problem.
In the solution to the first readers-writers problem, the reader processes share the following data structures:
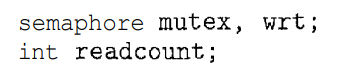
The semaphores mutex and wrt are initialized to 1; readcount is initialized to 0. The semaphore wrt is common to both reader and writer processes. The mutex semaphore is used to ensure mutual exclusion when the variable readcount is updated.

Fig 5.2 The structure of a writer process.
The readcount variable keeps track of how many processes are currently reading the object. The semaphore wrt functions as a mutual-exclusion semaphore for the writers. It is also used by the first or last reader that enters or exits the critical section. It is not used by readers who enter or exit while other readers are in their critical sections.

Fig 5.3
The code for a writer process is shown in Figure 5.2; the code for a reader process is shown in Figure 5.3. Note that, if a writer is in the critical section and n readers are waiting, then one reader is queued on wrt, and n - 1 readers are queued on mutex. Also observe that, when a writer executes signal (wrt), we may resume the execution of either the waiting readers or a single waiting writer. The selection is made by the scheduler.
The readers-writers problem and its solutions has been generalized to provide reader-writer locks on some systems. Acquiring a reader-writer lock requires specifying the mode of the lock: either read or write access.
When a process only wishes to read shared data, it requests the reader-writer lock in read mode; a process wishing to modify the shared data must request the lock in write mode. Multiple processes are permitted to concurrently acquire a reader-writer lock in read mode; only one process may acquire the lock for writing as exclusive access is required for writers
5.2 Reader-writer locks are most useful in the following situations:
i. In applications where it is easy to identify which processes only read shared data and which threads only write shared data.
ii. In applications that have more readers than writers. This is because reader-writer locks generally require more overhead to establish than semaphores or mutual exclusion locks, and the overhead for setting up a reader-writer lock is compensated by the increased concurrency of allowing multiple readers.
×
NOTE: Each Page Provides only 5 Questions & Answer
Below Page NAVIGATION Links are Provided...
All the Questions on Question Bank Is SOLVED
Below Page NAVIGATION Links are Provided...
All the Questions on Question Bank Is SOLVED
Advertisement
lIKE OUR CONTENT SUPPORT US BY FOLLOWING US ON INSTAGRAM : @futurevisionbie
For immediate Notification Join the Telegram Channel
×
SUGGESTION: SHARE WITH ALL THE STUDENTS AND FRIENDS -ADMIN