 MENU
MENU


NOTE!
Click on MENU to Browse between Subjects...17CS53 - DATABASE MANAGEMENT SYSTEM
Answer Script for Module 1
Solved Previous Year Question Paper
CBCS SCHEME
DATABASE MANAGEMENT SYSTEM
17CS53
[As per Choice Based Credit System (CBCS) scheme]
(Effective from the academic year 2019 -2020)
SEMESTER - V
Subject Code 17CS53
IA Marks 40
Number of Lecture Hours/Week 04
Exam Marks 60
These Questions are being framed for helping the students in the "FINAL Exams" Only
(Remember for Internals the Question Paper is set by your respective teachers).
Questions may be repeated, just to show students how VTU can frame Questions.
- ADMIN
The main characteristics of the database approach versus the file-processing approach are the following:
i. Self-describing nature of a database system
ii. Insulation between programs and data, and data abstraction
iii. Support of multiple views of the data
iv. Sharing of data and multiuser transaction processing
I.
SELF DESCRIBING NATURE OF DATABASE SYSTEM:
A fundamental characteristic of the database approach is that the database
system contains not only the database itself but also a complete definition
or description of the database structure and constraints
.
This definition is stored in the DBMS catalog, which contains information
such as the structure of each file, the type and storage format of each
data item, and various constraints on the data. The information stored in
the catalog is called meta-data
, and it describes the structure
of the primary database.
It is important to note that some newer types of database systems, known as
NOSQL systems, do not require meta-data. Rather the data is stored as self-describing data
that includes the data item names and
data values together in one structure
.
In traditional file processing
, data definition is
typically part of the application programs
themselves.
Hence, these programs are constrained to work with only one specific
database, whose structure is declared in the application programs. For
example, an application program written in C++ may have struct or class
declarations. Whereas file-processing
software can access only specific databases
, DBMS software
can access diverse databases by extracting the database definitions from
the catalog and using these definitions.
II.
INSULATION BETWEEN PROGRAMS AND DATA, AND DATA ABSTRACTION:
In traditional file processing, the structure of data files is embedded in
the application programs, so any changes to the structure of a file may
require changing all programs
that access that file.
By contrast, DBMS access programs do not require such changes in most
cases. The structure of data files is stored in the DBMS catalog separately
from the access programs. We call this property program-data independence.
For example, a file access program may be written in such a way that it can access only STUDENT records of the structure. If we want to add another piece of data to each STUDENT record, say the Birth_date, such a program will no longer work and must be changed. By contrast, in a DBMS environment, we only need to change the description of STUDENT records in the catalog to reflect the inclusion of the new data item Birth_date; no programs are changed. The next time a DBMS program refers to the catalog, the new structure of STUDENT records will be accessed and used.
User application programs can operate on the data by invoking the
operations through their names and arguments, regardless of how the
operations are implemented. This may be termed program-operation independence
.
The characteristic that allows program-data independence and
program-operation independence is called data abstraction
.
A DBMS provides users with a conceptual representation
of
data that does not include many of the details of how the data is stored or
how the operations are implemented.
Informally, a data model is a type of data abstraction that is used to provide this conceptual representation.
The data model uses logical concepts, such as objects, their properties,
and their interrelationships, that may be easier for most users to
understand than computer storage concepts. Hence, the data model hides storage and implementation details
that are not of
interest to most database users.
III.
SUPPORT OF MULTIPLE VIEWS OF THE DATA:
A database typically has many types of users, each of whom may require a
different perspective or view
of the database.
A view may be a subset of the database or it may contain virtual data that is derived from the database files but is not explicitly stored. Some users may not need to be aware of whether the data they refer to is stored or derived.
A multiuser DBMS whose users have a variety of distinct applications must provide facilities for defining multiple views.
For example, one user of the database may be interested only in accessing and printing the transcript of each student. A second user, who is interested only in checking that students have taken all the prerequisites of each course for which the student registers, may require the view.
IV.
SHARING OF DATA AND MULTIUSER TRANSACTION PROCESSING:
A multiuser DBMS, as its name implies, must allow multiple users to access the database at the same time. This is essential if data for multiple applications is to be integrated and maintained in a single database.
The DBMS must include concurrency control
software to
ensure that several users trying to update the same data do so in a
controlled manner so that the result of the updates is correct. For
example, when several reservation agents try to assign a seat on an airline
flight, the DBMS should ensure that each seat can be accessed by only one
agent at a time for assignment to a passenger.
These types of applications are generally called online transaction processing (OLTP) applications
. A
fundamental role of multiuser DBMS software is to ensure that concurrent
transactions operate correctly and efficiently.
The concept of a transaction has become central to many database applications. A transaction is an executing program or process that includes one or more database accesses, such as reading or updating of database records.
Each transaction is supposed to execute a logically correct database
access if executed in its
entirety without interference from other transactions.
The DBMS must enforce several transaction properties. The isolation property
ensures that each transaction appears
to execute in isolation from other transactions, even though hundreds of
transactions may be executing concurrently.
The atomicity property
ensures that either all the
database operations in a transaction are executed or none are.
2.1 THREE-SCHEMA ARCHITECTURE
The goal of the three-schema architecture, illustrated in Figure 2.1, is to separate the user applications from the physical database. In this architecture, schemas can be defined at the following three levels:
i.
The internal level
has an internal schema
, which describes the physical storage structure of the database. The
internal schema uses a physical data model and describes the complete
details of data storage and access paths for the database.
ii.
The conceptual level
has a conceptual schema, which
describes the structure of the whole database for a community of users. The
conceptual schema hides the details of physical storage structures and
concentrates on describing entities, data types, relationships, user
operations, and constraints. Usually, a representational data model is used
to describe the conceptual schema when a database system is implemented.
This implementation conceptual schema
is often based on aconceptual schema design
in a high-level data model.
iii.
The external or view level
includes a number of external
schemas or user views. Each external schema describes the part of the
database that a particular user group is interested in and hides the rest
of the database from that user group. As in the previous level, each
external schema is typically implemented using a representational data
model, possibly based on an external schema
design in a
high-level conceptual data model.
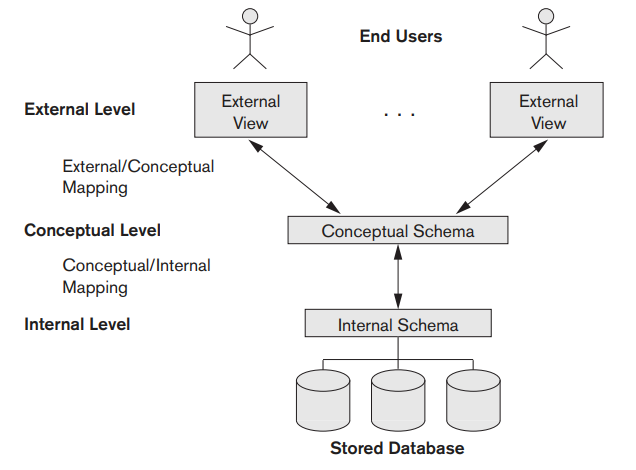
Fig 2.1: Three-Schema Architecture
The three-schema architecture is a convenient tool with which the user can visualize the schema levels in a database system. Most DBMSs do not separate the three levels completely and explicitly, but they support the three-schema architecture to some extent. Some older DBMSs may include physical-level details in the conceptual schema.
2.2 Mapping - Three-Schema Architecture
In the three-schema architecture, each user group refers to its own external schema. Hence, the DBMS must transform a request specified on an external schema into a request against the conceptual schema, and then into a request on the internal schema for processing over the stored database.
If the request is a database retrieval, the data extracted from the stored
database must be reformatted to match the user's external view. The
processes of transforming requests and results between levels are called mappings
.
These mappings may be time-consuming, so some DBMSs-especially those that are meant to support small databases-do not support external views. Even in such systems, however, it is necessary to transform requests between the conceptual and internal levels.
2.3 Schema Definition language support
In current DBMSs, the preceding types of languages are usually not considered distinct languages; rather, a comprehensive integrated language is used that includes constructs for conceptual schema definition, view definition, and data manipulation.
Storage definition is typically kept separate, since it is used for defining physical storage structures to fine-tune the performance of the database system, which is usually done by the DBA staff.
Discuss with examples, different types of architectures. (7-Marks) (2a)
(Dec.2017/Jan.2018)The different types of Architecture are as follows:
1.1.1
Centralized DBMSs Architecture:
The reason was that in older systems, most users accessed the DBMS via computer terminals that did not have processing power and only provided display capabilities. Therefore, all processing was performed remotely on the computer system housing the DBMS, and only display information and controls were sent from the computer to the display terminals, which were connected to the central computer via various types of communications networks.
As prices of hardware declined, most users replaced their terminals with PCs and workstations, and more recently with mobile devices. At first, database systems used these computers similarly to how they had used display terminals, so that the DBMS itself was still a centralized DBMS in which all the DBMS functionality, application program execution, and user interface processing were carried out on one machine.
Figure 3.1 illustrates the physical components in a centralized architecture. Gradually, DBMS systems started to exploit the available processing power at the user side, which led to client/server DBMS architectures.
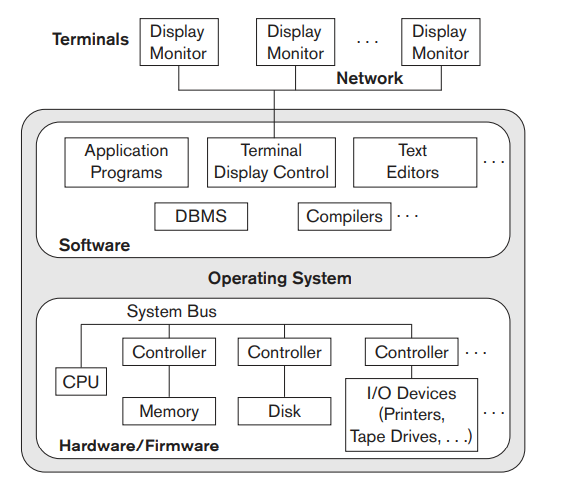
Fig 3.1: A physical centralized architecture
1.1.2
Basic Client/Server Architectures:
The client/server architecture
was developed to deal with
computing environments in which a large number of PCs, workstations, file
servers, printers, database servers, Web servers, e-mail servers, and other
software and equipment are connected via a network.
The idea is to define specialized servers with specific functionalities. For example, it is possible to connect a number of PCs or small workstations as clients to a file server that maintains the files of the client machines. Another machine can be designated as a printer server by being connected to various printers; all print requests by the clients are forwarded to this machine. Web servers or e-mail servers also fall into the specialized server category
The resources provided by specialized servers can be accessed by many client machines. The client machines provide the user with the appropriate interfaces to utilize these servers, as well as with local processing power to run local applications. This concept can be carried over to other software packages, with specialized programs-such as a CAD (computer-aided design) package-being stored on specific server machines and being made accessible to multiple clients.
Fig 3.3 illustrates client/server architecture at the logical level; Figure 3.4 is a simplified diagram that shows the physical architecture. Some machines would be client sites only (for example, mobile devices or workstations/PCs that have only client software installed). Other machines would be dedicated servers, and others would have both client and server functionality.
The concept of client/server architecture assumes an underlying framework that consists of many PCs/workstations and mobile devices as well as a smaller number of server machines, connected via wireless networks or LANs and other types of computer networks.
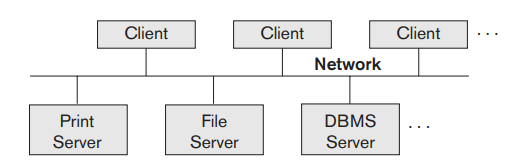
Fig 3.3: Logical two-tier client/server architecture.
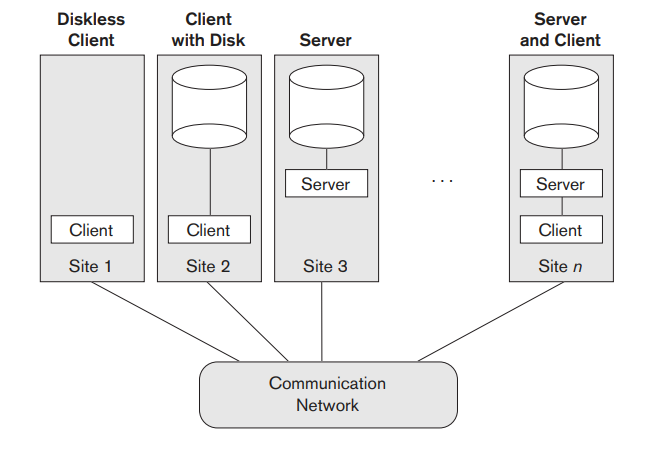
Fig 3.4: Physical two-tier client/server architecture.
1.1.3
Two-Tier Client/Server Architectures for DBMS:
In relational database management systems (RDBMSs), many of which started as centralized systems, the system components that were first moved to the client side were the user interface and application programs. Because SQL provided a standard language for RDBMSs, this created a logical dividing point between client and server.
Hence, the query and transaction functionality related to SQL processing remained on the server side. In such an architecture, the server is often called a query server or transaction server because it provides these two functionalities. In an RDBMS, the server is also often called an SQL server.
The user interface programs and application programs can run on the client side. When DBMS access is required, the program establishes a connection to the DBMS (which is on the server side); once the connection is created, the client program can communicate with the DBMS.
A standard called Open Database Connectivity (ODBC) provides an application programming interface (API), which allows client-side programs to call the DBMS, as long as both client and server machines have the necessary software installed.
A client program can actually connect to several RDBMSs and send query and transaction requests using the ODBC API, which are then processed at the server sites.
The architectures described here are called two-tier architectures because the software components are distributed over two systems: client and server. The advantages of this architecture are its simplicity and seamless compatibility with existing systems. The emergence of the Web changed the roles of clients and servers, leading to the three-tier architecture.
1.1.4
Three-Tier and n-Tier Architectures for Web Applications:
Many Web applications use an architecture called the three-tier architecture, which adds an intermediate layer between the client and the database server. This is demonstrated in Fig 3.5
This intermediate layer or middle tier is called the application server or the Web server, depending on the application. This server plays an intermediary role by running application programs and storing business rules (procedures or constraints) that are used to access data from the database server.
It can also improve database security by checking a client's credentials before forwarding a request to the database server
Clients contain user interfaces and Web browsers.
The intermediate server accepts requests from the client, processes the request and sends database queries and commands to the database server, and then acts as a conduit for passing (partially) processed data from the database server to the clients, where it may be processed further and filtered to be presented to the users.
The bottom layer includes all data management services. The middle layer can also act as a Web server, which retrieves query results from the database server and formats them into dynamic Web pages that are viewed by the Web browser at the client side. The client machine is typically a PC or mobile device connected to the Web.
Advances in encryption and decryption technology make it safer to transfer sensitive data from server to client in encrypted form, where it will be decrypted. The latter can be done by the hardware or by advanced software.
This technology gives higher levels of data security, but the network security issues remain a major concern. Various technologies for data compression also help to transfer large amounts of data from servers to clients over wired and wireless networks.
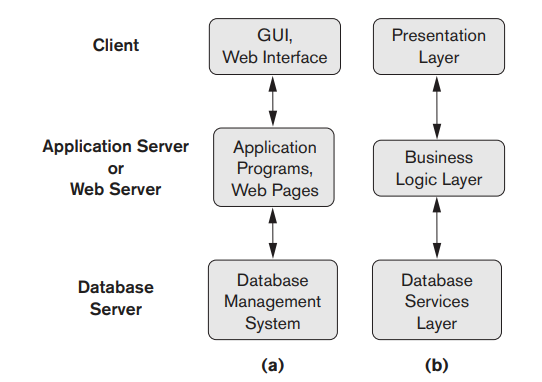
Fig 3.5: Logical three-tier client/server architecture, with a couple of commonly used nomenclatures.
Below Page NAVIGATION Links are Provided...
All the Questions on Question Bank Is SOLVED
Follow our Instagram Page:
FutureVisionBIE
https://www.instagram.com/futurevisionbie/
Message: I'm Unable to Reply to all your Emails
so, You can DM me on the Instagram Page & any other Queries.