 MENU
MENU


NOTE!
Click on MENU to Browse between Subjects...17CS53 - DATABASE MANAGEMENT SYSTEM
Answer Script for Module 5
Solved Previous Year Question Paper
CBCS SCHEME
DATABASE MANAGEMENT SYSTEM
DBMS
[As per Choice Based Credit System (CBCS) scheme]
(Effective from the academic year 2019 -2020)
SEMESTER - V
Subject Code 17CS53
IA Marks 40
Number of Lecture Hours/Week 04
Exam Marks 60
These Questions are being framed for helping the students in the "FINAL Exams" Only
(Remember for Internals the Question Paper is set by your respective teachers).
Questions may be repeated, just to show students how VTU can frame Questions.
- ADMIN
There are many more details, and the newer standards have more commands for transaction processing. The basic definition of an SQL transaction is similar to our already defined concept of a transaction. That is, it is a logical unit of work and is guaranteed to be atomic. A single SQL statement is always considered to be atomic-either it completes execution without an error or it fails and leaves the database unchanged.
With SQL, there is no explicit Begin_Transaction statement. Transaction initiation is done implicitly when particular SQL statements are encountered. However, every transaction must have an explicit end statement, which is either a COMMIT or a ROLLBACK. Every transaction has certain characteristics attributed to it. These characteristics are specified by a SET TRANSACTION statement in SQL. The characteristics are the access mode, the diagnostic area size, and the isolation level.
The access mode
can be specified as READ ONLY or READ
WRITE. The default is READ WRITE, unless the isolation level of READ
UNCOMMITTED is specified (see below), in which case READ ONLY is assumed. A
mode of READ WRITE allows select, update, insert, delete, and create
commands to be executed. A mode of READ ONLY, as the name implies, is
simply for data retrieval.
The diagnostic area
size option, DIAGNOSTIC SIZE n,
specifies an integer value n, which indicates the number of conditions that
can be held simultaneously in the diagnostic area. These conditions supply
feedback information (errors or exceptions) to the user or program on the n
most recently executed SQL statement.
The isolation level
option is specified using the statement ISOLATION LEVEL , where the value
for can be READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, or
SERIALIZABLE. 15 The default isolation level is SERIALIZABLE, although some
systems use READ COMMITTED as their default. The use of the term
SERIALIZABLE here is based on not allowing violations that cause dirty
read, unrepeatable read, and phantoms,
If a transaction executes at a lower isolation level than SERIALIZABLE, then one or more of the following three violations may occur:
a. Dirty read:
A transaction T1 may read the update of a
transaction T2, which has not yet committed. If T2 fails and is aborted,
then T1 would have read a value that does not exist and is incorrect.
b. Non-repeatable read:
A transaction T1 may read a given
value from a table. If another transaction T2 later updates that value and
T1 reads that value again, T1 will see a different value.
c. Phantoms:
A transaction T1 may read a set of rows from
a table, perhaps based on some condition specified in the SQL WHERE-clause.
Now suppose that a transaction T2 inserts a new row r that also satisfies
the WHERE-clause condition used in T1, into the table used by T1. The
record r is called a phantom record because it was not there when T1 starts
but is there when T1 ends. T1 may or may not see the phantom, a row that
previously did not exist. If the equivalent serial order is T1 followed by
T2, then the record r should not be seen; but if it is T2 followed by
T1,then the phantom record should be in the result given to T1. If the
system cannot ensure the correct behavior, then it does not deal with the
phantom record problem.
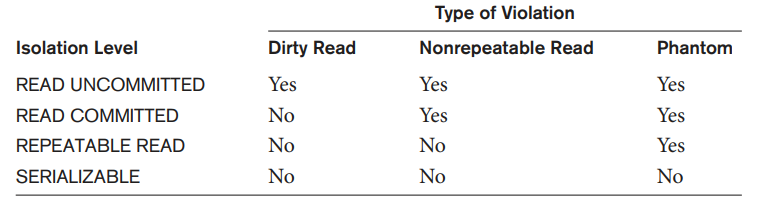
Table 6.1: Possible Violations Based on Isolation Levels as Defined in SQL
Table 6.1 summarizes the possible violations for the different isolation levels. An entry of Yes indicates that a violation is possible and an entry of No indicates that it is not possible. READ UNCOMMITTED is the most forgiving, and SERIALIZABLE is the most restrictive in that it avoids all three of the problems mentioned above.
A sample SQL transaction might look like the following:
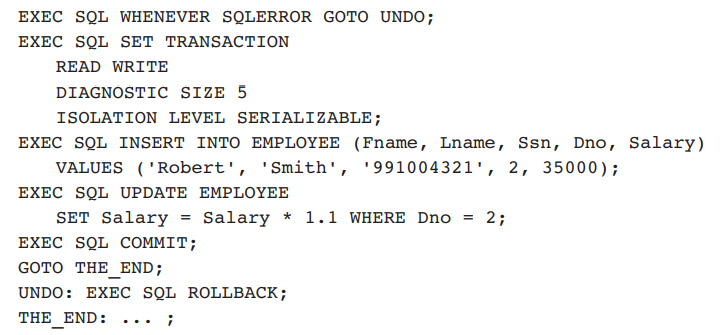
The above transaction consists of first inserting a new row in the EMPLOYEE table and then updating the salary of all employees who work in department 2. If an error occurs on any of the SQL statements, the entire transaction is rolled back. This implies that any updated salary (by this transaction) would be restored to its previous value and that the newly inserted row would be removed.
In the immediate update techniques
, the database may be
updated by some operations of a transaction before the transaction reaches
its commit point. However, these operations must also be recorded in the
log on disk by force-writing before they are applied to the database on
disk, making recovery still possible. If a transaction fails after
recording some changes in the database on disk but before reaching its
commit point, the effect of its operations on the database must be undone;
that is, the transaction must be rolled back.
In the general case of immediate update, both undo and redo may be required
during recovery. This technique, known as the UNDO/REDO algorithm
, requires both operations during
recovery and is used most often in practice.
A variation of the algorithm where all updates are required to be recorded
in the database on disk before a transaction commits requiresundo only, so it is known as the UNDO/NO-REDO algorithm
.
The UNDO and REDO operations are required to be idempotent
-that is, executing an operation multiple times is equivalent to executing
it just once. In fact, the whole recovery process should be idempotent
because if the system were to fail during the recovery process, the next
recovery attempt might UNDO and REDO certain write_item operations that had
already been executed during the first recovery process. The result of
recovery from a system crash during recovery should be the same as the
result of recovering when there is no crash during recovery!
7.1 Recovery Techniques Based on Immediate Update
In these techniques, when a transaction issues an update command, the database on disk can be updated immediately, without any need to wait for the transaction to reach its commit point. Notice that it is not a requirement that every update be applied immediately to disk; it is just possible that some updates are applied to disk before the transaction commits.
Provisions must be made for undoing the effect of update operations that
have been applied to the database by a failed transaction. This is
accomplished by rolling back the transaction and undoing the effect of the
transaction's write_item operations. Therefore, theUNDO-type log entries
, which include the old value (BFIM
) of the item, must be stored in the log.
Because UNDO can be needed during recovery, these methods follow a steal strategy
for deciding when updated main memory
buffers can be written back to disk
Theoretically, we can distinguish two main categories of immediate update algorithms
i. If the recovery technique ensures that all updates of a transaction are
recorded in the database on disk before the transaction commits, there is
never a need to REDO
any operations of committed
transactions. This is called the UNDO/NO-REDO recovery algorithm
. In this method, all
updates by a transaction must be recorded on disk before the transaction
commits, so that REDO is never needed
. Hence, this method
must utilize the steal/force strategy for deciding when updated main memory
buffers are written back to disk
ii. If the transaction is allowed to commit before all its changes are
written to the database, we have the most general case, known as the UNDO/REDO recovery algorithm
. In this case, the
steal/no-force strategy is applied. This is also the most complex
technique, but the most commonly used in practice. We will outline an
UNDO/REDO recovery algorithm and leave it as an exercise for the reader to
develop the UNDO/NO-REDO variation
Procedure RIU_M (UNDO/REDO with checkpoints).
a. Use two lists of transactions maintained by the system: the committed transactions since the last checkpoint and the active transactions.
b. Undo all the write_item operations of the active (uncommitted) transactions, using the UNDO procedure. The operations should be undone in the reverse of the order in which they were written into the log.
c. Redo all the write_item operations of the committed transactions from the log, in the order in which they were written into the log, using the REDO procedure defined earlier.
The UNDO procedure is defined as follows:
Procedure UNDO (WRITE_OP). Undoing a write_item operation write_op consists of examining its log entry [write_item, T, X, old_value, new_value] and setting the value of item X in the database to old_value, which is the before image (BFIM). Undoing a number of write_item operations from one or more transactions from the log must proceed in the reverse order from the order in which the operations were written in the log.
The definition of serializable schedule is as follows: A schedule S of n transactions is serializable if it is equivalent to some serial schedule of the same n transactions.
9.1 How Serializability Is Used for Concurrency Control
A schedule S is (conflict) serializable-that is, S is (conflict) equivalent to a serial schedule-is tantamount to saying that S is correct. Being serializable is distinct from being serial, however.
A serial schedule represents inefficient processing because no interleaving of operations from different transactions is permitted. This can lead to low CPU utilization while a transaction waits for disk I/O, or for a long transaction to delay other transactions, thus slowing down transaction processing considerably.
A serializable schedule gives the benefits of concurrent execution without
giving up any correctness. In practice, it is difficult to test for the
serializability of a schedule. The interleaving of operations from
concurrent transactions-which are usually executed as processes by the
operating system-is typically determined by the operating system scheduler,
which allocates resources to all processes. Factors such as system load,
time of transaction submission, and priorities of processes contribute to
the ordering of operations in a schedule. Hence, it is difficult to
determine how the operations of a schedule will be interleaved beforehand
to ensure serializability
.
If transactions are executed at will and then the resulting schedule is tested for serializability, we must cancel the effect of the schedule if it turns out not to be serializable. This is a serious problem that makes this approach impractical. The approach taken in most commercial DBMSs is to design protocols (sets of rules) that-if followed by every individual transaction or if enforced by a DBMS concurrency control subsystem-will ensure serializability of all schedules in which the transactions participate. Some protocols may allow non-serializable schedules in rare cases to reduce the overhead of the concurrency control method.
10.1 Introduction:
A timestamp is a unique identifier created by the DBMS to identify a transaction. Typically, timestamp values are assigned in the order in which the transactions are submitted to the system, so a timestamp can be thought of as the transaction start time. We will refer to the timestamp of transaction T as TS(T). Concurrency control techniques based on timestamp ordering do not use locks; hence, deadlocks cannot occur.
Timestamps can be generated in several ways. One possibility is to use a counter that is incremented each time its value is assigned to a transaction. The transaction timestamps are numbered 1, 2, 3, … in this scheme. A computer counter has a finite maximum value, so the system must periodically reset the counter to zero when no transactions are executing for some short period of time.
10.2 The Timestamp Ordering Algorithm for Concurrency Control:
The idea for this scheme is to enforce the equivalent serial order on the transactions based on their timestamps. A schedule in which the transactions participate is then serializable, and the only equivalent serial schedule permitted has the transactions in order of their timestamp values. This is called timestamp ordering (TO).
Notice how this differs from 2PL, where a schedule is serializable by being equivalent to some serial schedule allowed by the locking protocols. In timestamp ordering, however, the schedule is equivalent to the particular serial order corresponding to the order of the transaction timestamps.
The algorithm allows interleaving of transaction operations, but it must ensure that for each pair of conflicting operations in the schedule, the order in which the item is accessed must follow the timestamp order. To do this, the algorithm associates with each database item X two timestamp (TS) values:
a. read_TS(X). The read timestamp of item X is the largest timestamp among all the timestamps of transactions that have successfully read item X-that is, read_TS(X) = TS(T), where T is the youngest transaction that has read X successfully.
b. write_TS(X). The write timestamp of item X is the largest of all the timestamps of transactions that have successfully written item X-that is, write_TS(X) = TS(T), where T is the youngest transaction that has written X successfully. Based on the algorithm, T will also be the last transaction to write item X.
10.2.1
Basic Timestamp Ordering (TO):
Whenever some transaction T tries to issue a read_item(X) or a
write_item(X) operation, the basic TO
algorithm compares
the timestamp of T with read_TS(X) and write_TS(X) to ensure that the
timestamp order of transaction execution is not violated. If this order is
violated, then transaction T is aborted and resubmitted to the system as a
new transaction with a new timestamp
.
If T is aborted and rolled back, any transaction T1 that may have used a
value written by T must also be rolled back. Similarly, any transaction T2
that may have used a value written by T1 must also be rolled back, and so
on. This effect is known as cascading rollback
and is one
of the problems associated with basic TO, since the schedules produced are
not guaranteed to be recoverable.
An additional protocol must be enforced to ensure that the schedules are recoverable, cascadeless, or strict. We first describe the basic TO algorithm here. The concurrency control algorithm must check whether conflicting operations violate the timestamp ordering in the following two cases:
i.
Whenever a transaction T issues a write_item(X) operation, the
following check is performed:
a. If read_TS(X) > TS(T) or if write_TS(X) > TS(T), then abort and roll back T and reject the operation. This should be done because some younger transaction with a timestamp greater than TS(T)-and hence after T in the timestamp ordering-has already read or written the value of item X before T had a chance to write X, thus violating the timestamp ordering.
b. If the condition in part (a) does not occur, then execute the write_item(X) operation of T and set write_TS(X) to TS(T).
ii. Whenever a transaction T issues a read_item(X) operation, the
following check is performed:
a. If write_TS(X) > TS(T), then abort and roll back T and reject the operation. This should be done because some younger transaction with timestamp greater than TS(T)-and hence after T in the timestamp ordering-has already written the value of item X before T had a chance to read X.
b. If write_TS(X) ≤ TS(T), then execute the read_item(X) operation of T and set read_TS(X) to the larger of TS(T) and the current read_TS(X).
Whenever the basic TO algorithm detects two conflicting operations that
occur in the incorrect order, it rejects the later of the two operations by
aborting the transaction that issued it. The schedules produced by basic TO
are hence guaranteed to be conflict serializable
.
10.2.2
Strict Timestamp Ordering (TO).
A variation of basic TO called strict TO ensures that the schedules are both strict (for easy recoverability) and (conflict) serializable. In this variation, a transaction T issues a read_item(X) or write_item(X) such that TS(T) > write_TS(X) has its read or write operation delayed until the transaction T′ that wrote the value of X (hence TS(T′) = write_TS(X)) has committed or aborted.
To implement this algorithm, it is necessary to simulate the locking of an item X that has been written by transaction T′ until T′ is either committed or aborted. This algorithm does not cause deadlock, since T waits for T′ only if TS(T) > TS(T′).
10.2.3 Thomas's Write Rule.
A modification of the basic TO algorithm, known as Thomas's write rule, does not enforce conflict serializability, but it rejects fewer write operations by modifying the checks for the write_item(X) operation as follows:
a. If read_TS(X) > TS(T), then abort and roll back T and reject the operation.
b. If write_TS(X) > TS(T), then do not execute the write operation but continue processing. This is because some transaction with timestamp greater than TS(T)-and hence after T in the timestamp ordering-has already written the value of X. Thus, we must ignore the write_item(X) operation of T because it is already outdated and obsolete. Notice that any conflict arising from this situation would be detected by case (1).
c. If neither the condition in part (1) nor the condition in part (2) occurs, then execute the write_item(X) operation of T and set write_TS(X) to TS(T).
Below Page NAVIGATION Links are Provided...
All the Questions on Question Bank Is SOLVED
Follow our Instagram Page:
FutureVisionBIE
https://www.instagram.com/futurevisionbie/
Message: I'm Unable to Reply to all your Emails
so, You can DM me on the Instagram Page & any other Queries.